llms.txt nedir, kimin için önemli?
Önerilen llms.txt standardı, büyük dil modellerine "neyi nerede okusun?" sorusunda yol göstermek için tasarlandı. llmstxt.org önerisi, adoption oranları, SE Ranking verileri ve topluluk tartışmaları — Türkçe özet rehber.


Yazar
Teknik SEO, yapay zekâ arama ve GEO konularında uygulamalı rehberler hazırlar.
Geliştiricilere ve pazarlamacılara, büyük dil modellerinin (LLM) sitenizi "anlamasına" yardımcı olmak için kök dizine llms.txt eklenmesi sıkça öneriliyor. Peki llms.txt tam olarak nedir, bugün kimin tarafından okunuyor ve sizin için öncelikli mi?
llms.txt nedir?
llms.txt, web sitelerinden yapılandırılmış içeriğe giden yolları toplayarak LLM’lerin içeriğe erişimini ve yorumlamasını kolaylaştırmayı hedefleyen öneri düzeyinde bir standarttır. Tam öneri metni llmstxt.org adresinde; Jeremy Howard’ın 3 Eylül 2024 tarihli açıklamasıyla yayımlanmıştır.
Kısaca, dosya; API dokümantasyonu, iade politikaları, ürün taksonomisi gibi yüksek değerli kaynaklara giden, insan ve makine tarafından okunabilir seçilmiş bir harita sunmayı amaçlar. Amaç, modele tüm siteyi taramak zorunda bırakmadan ilgili içeriğin nerede olduğunu netleştirmek. Resmî formata dair ekran örnekleri ve şema için bkz. llmstxt.org — sitemap ve robots.txt ile aynı değil, birbirlerini tamamlamayı hedeflerler.
Teoride mantıklı: Zaten robots.txt ve sitemap.xml ile arama motorlarına tarama ve keşif sinyali veriyoruz; aynı mantığın LLM tarafı için sürülmesi fikri hızla yayıldı. Ancak bugün itibarıyla hiçbir büyük LLM sağlayıcısı llms.txt’yi resmî tarama/çıkarım protokolü olarak duyurmadı (OpenAI, Anthropic, Google arama ürünleri açısından bu dosya, robots.txt gibi "mutlak kural" değil).
Google, Nisan 2025’e ilişkin Agent2Agent (A2A) protokolü kapsamında llms.txtye referans verdi — bu, öneriyi başka bir öneri yığınına ekleme gibi yorumlanabilir; Google’ın alan adınızda bu dosyayı düzenli olarak taramaya başladığını iddia eden resmî bir taahhüt yok.
Özetle: llms.txt deneysel, topluluk odaklı bir çerçeve; büyük sağlayıcılar açısından "mutlak standart" statüsünde değil.
robots.txt hâlâ zorunlu lisans
llms.txt organik veya AI görünürlüğünü garanti etmez; robots.txt ise tarama ve indeksleme erişimini fiilen belirlediğinden hâlâ kritik öneme sahiptir. Kapsamlı site audit ve teknik SEO süreçlerinde robots, yönlendirme ve log analizleri önceliklidir.
Örnek llms.txt yapısı
Öneri, Markdown belgesi olarak kök yolda barındırılmalıdır. H2 başlıkları altında, önemli kaynaklara giden [ad](https://...) listeleri ve kısa açıklamalar bulunur. Aşağıdaki yapı tipik bir şablondur:
# Siteniz
## Dokümanlar
- /api.md — Kimlik doğrulama, limitler, örnek istekler
## Politikalar
- /iade.md — İade koşulları
## Ürün
- /katalog.md — Kategoriler ve SKU indeksi
- Basit bir Markdown dosyasıyla başlayın.
- Kaynakları türlerine göre H2’lerle gruplayın.
- Mümkünse sayfa başına sade, bağlantı dostu
.mdtürevlerini aynı URL yapısında sunun (öneride bu da var). - Düzenli güncelleyin; eski kırık bağlantı LLM’e yanlış sinyal verir.
- Alan adı kökünde yayımlayın:
https://ornek.com/llms.txt
SEOART olarak kökte iki dosya yayımlıyoruz: /llms.txt (özet rehber indeksi) ve /llms-full.txt (açıklamaları genişletilmiş sürüm).
Harici llms.txt üreteçleri (ör. Firecrawl) sitemap’inizden başlayıp bir taslak çıkarabilir; çıktıyı mutlaka elden geçirin.
Kimler kullanıyor?
Topluluk indeksi directory.llmstxt.cloud herkese açık llms.txt örneklerini listeler. Örnek alınabilecek markalar arasında Mintlify (dokümantasyon), Tinybird (veri API’leri), Cloudflare (güvenlik/performans dokümanları) ve Anthropic (kendi llms.txt’sini yayımlıyor) sayılabilir. Bu dağılım, formatın özellikle geliştirici belgeleri ağırlıklı sitelerde yayıldığını gösterir.
Buna karşılık büyük sağlayıcıların tarayıcı taraflı resmî durumları farklı:
- OpenAI (GPTBot):
robots.txtkurallarına uyum;llms.txtresmî ajan protokolü değil. - Anthropic: Kendi
llms.txt’sini yayımlıyor; tarayıcının aynı standardı izlediğine dair açık beyan sınırlı. - Google (Gemini / arama altyapısı):
Google-Extendedgibi yönergeler;llms.txtayrı bir zorunluluk değil.
llms.txt "işe yarıyor" mu?
Bugün elimizdeki empirik kanıt sınırlı: llms.txt’nin yapay zekâ cevaplarındaki alıntı hacmini veya tıklama getirisini artırdığına dair bağımsız, tekrarlanabilir geniş çaplı bir çalışma yok. Hiçbir büyük sağlayıcı da "bu dosyayı her zaman okuyoruz" demiyor.
Yine de uygulaması hafif: Zaten iyi organize dokümanınız varsa Markdown bir indeks çıkarmak kısa sürer; teorik faydayı, düşük maliyetle test edilebilir bir "opsiyon" gibi görmek mümkün. Erken dönemde deneyen markalar, olası ileri standarda hazırlanmış olur.
Bildiğim kadarıyla yapay zekâ hizmetlerinin hiçbiri LLMs.TXT kullandığını söylemedi; sunucu loglarına baktığınızda dosyayı denetlemediklerini de görebilirsiniz. Bana kalırsa eski keywords meta etiketine benziyor — site sahibi sitenin ne hakkında olduğunu iddia ediyor… (Gerçekten öyle mi? Doğrudan siteye bakmak daha mantıklı değil mi?)
— John Mueller, Google arama desteği; İngilizce özgün söyleşiye dayalı çeviri/özet, Search Engine Journal.
Mueller’in benzetmesi: iddia edilen içerikla gerçek tarama sinyalinin aynı olmayabileceğini, kontrol edilecek nokta olarak doğrudan site ve loglar olduğunu vurguluyor; bu, "dosya var, bitti" beklentisine karşı sağlıklı bir denge.
Arama altyapısı tarafında da yapay zekâ açıklamaları çoğunlukla klasik tarama, yapılandırılmış veri ve içerik sinyalleriyle beslenmeye devam ediyor; SGE / AI Overview rehberimizde bu kanalları ayrıntılı işliyoruz.
Adoption: Veriler ne söylüyor? (SE Ranking)
SE Ranking’in yaklaşık 300.000 alan adı üzerindeki taramalarına göre, geçerli bir llms.txt yalnızca %10,13 oranında tespit edilebiliyor — neredeyse her 10 siteden 9’unda dosya yok. Görsel: SE Ranking, Kasım 2025 (aşağıdaki şema).
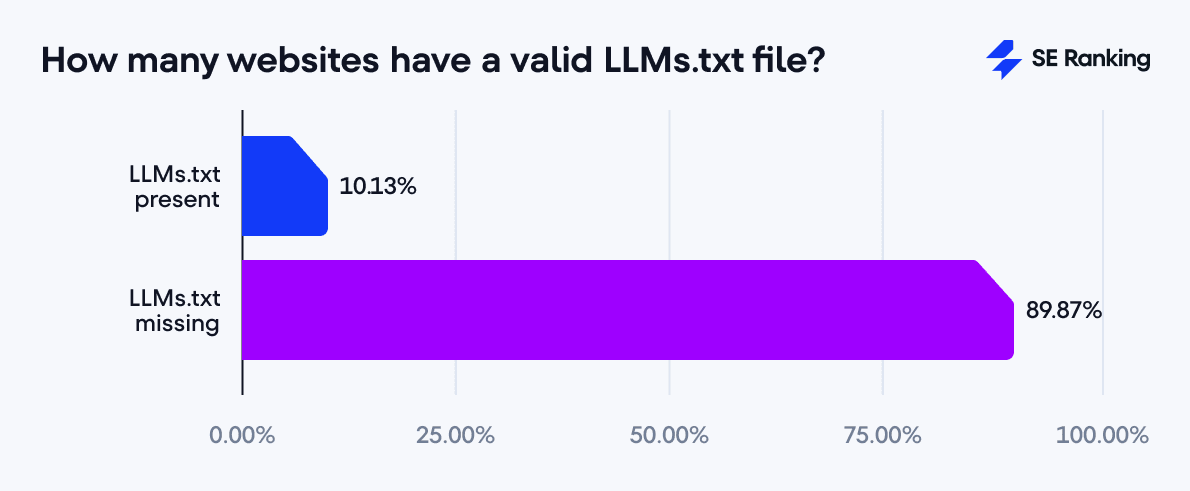
Yüksek trafik, daha yüksek adoption mu?
Büyük ve otoriter sitelerin yeni standartlara ilk uyanlar olacağı varsayımı doğal. Ancak SE Ranking, trafik dilimine göre kırdığında tablo beklenen yönde değil: düşük trafik (0–100 ziyaret) %9,88, orta (1.000–5.000) %10,54, 100.000+ ziyaret %8,27 ile en düşük oranı gösteriyor. Yani "her zaman büyükler önde" desem de veri bunu doğrulamıyor.
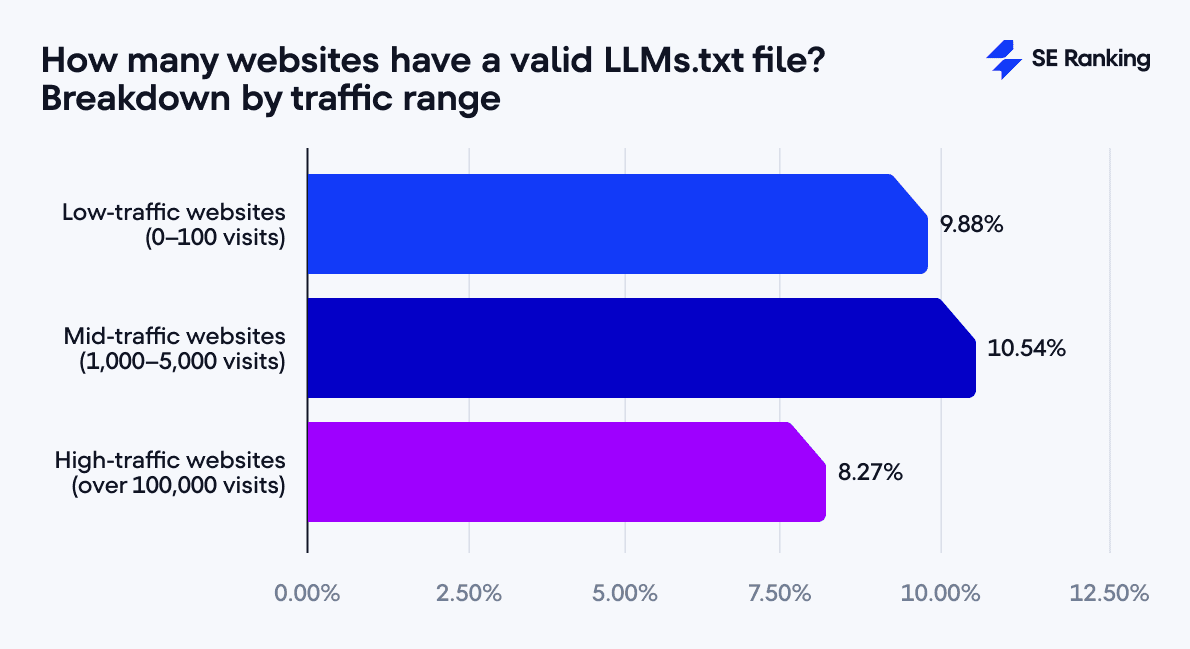
300.000 alan adı analizi, dosyanın yapay zekâ sistemlerinin sizi bugün nasıl alıntıladığı "üzerine tek başına sihirli çözüm" olmadığını hatırlatıyor. Buna rağmen dosyayı eklemek, bir sonraki indeksleme/çıkarım dalgasına düşük eforla hazırlanmanın yollarından biri; bugün "isteğe bağlı", yarın "iyi pratik" hâline gelirse sizi geride bırakmayacak türden bir sigorta gibi düşünülebilir.
Reddit tartışmasından notlar (r/SEO)
r/SEO topluluğunda llms.txt ve önemi etrafında dönen tartışmalarda tekrar eden temalar (özet):
- Tanım netliği: Yeni gelenler dosyayı, robots.txt veya sitemap gibi resmî tarama kuralı zannedebiliyor; aslında öneri düzeyinde ve evrensel uygulama yok.
- Önceliklendirme: Düşük bütçeli ekipler önce çekirdek teknik SEO + içerik + ölçüm (GSC, analitik) demeyi, llms.txt’yi buna eklenecek hafif bir kalem gibi konumlandırıyor.
- Şüphecilik: Sunucu loglarında
llms.txtisteğinin nadir veya belirsiz görülmesi, "henüz zorunlu tüketilmedi" yorumlarını körüklüyor. - İleriye dönük deneme: Yine de efor düşük olduğundan, dokümantasyonu güçlü e-ticaret / SaaS sitelerinde "şimdiden koy, güncel tut" diyenler var.
Bu maddeler topluluk yorumlarının derlenmiş özetidir; yatırım ve hukuk kararları için projenize özel değerlendirme yapın.
Sonuç: SEOART bakış açısı
llms.txt, GEO ve AI SEO gündeminizin yerine geçen bir sihir değil; fakat içerik mimarinizi zaten netleştirdiyseniz, tek dosyayla dışarıya "buradan başla" demek ilerideki ajan/LLM entegrasyonlarına yardımcı olabilir. Öncelik: teknik sağlık, ölçülebilir organik büyüme ve güven sinyalleri. İlgili: AEO rehberi, topical authority, SGE / AI Overview.

Oktay Çomak
Kurucu & SEO Stratejisti, SEOART
Kurumsal SEO'da veri disiplini ve ölçülebilir iş etkisine odaklanıyoruz; yol haritanızı birlikte netleştirelim.
LinkedInSEO yol haritanızı birlikte çizelim
Teknik sağlık, içerik uyumu ve görünürlük için ücretsiz ön analiz talep edin; öncelikli bulgularla sonraki adımları konuşalım.