ChatGPT Hangi Sayfayı Kaynak Gösteriyor? 1,4 Milyon Prompt Araştırması
ChatGPT'nin 1,4 milyon prompt üzerinde yapılan analizde hangi sayfaları kaynak gösterdiği, ref_type hiyerarşisi, semantik benzerlik ve sayfa yaşının atıflar üzerindeki etkisi inceleniyor.

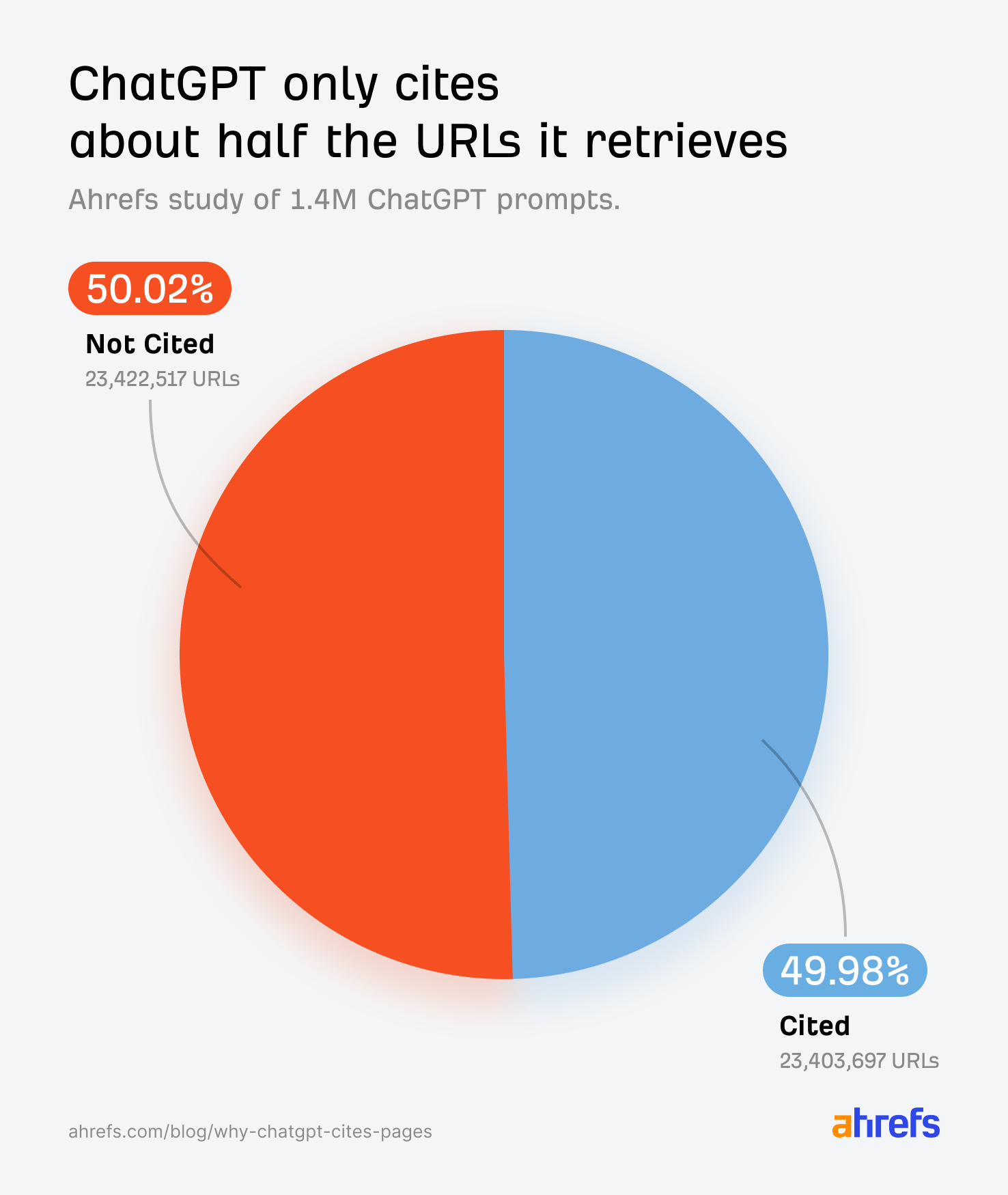
ChatGPT bir soruyu yanıtlarken onlarca URL alır; ancak yapılan araştırmaya göre bu URL'lerin yalnızca yaklaşık %50'si gerçek bir atıf olarak yanıtta yer alır. Peki aynı sorguda geri alınan iki sayfa arasında bir tanesi atıf kazanırken diğeri neden görmezden gelinir? Cevap, içerik kalitesinden çok daha erken bir aşamada — yapay zekanın sayfayı açmadan önce verdiği kararda — gizlidir.
Araştırmacı Dan Petrovic'in bulgularına göre ChatGPT her URL'yi, sayfa başlığı, kısa bir özet metin (snippet), URL'nin kendisi ve bir kimlik numarasından oluşan bir meta veri paketiyle birlikte alır. Model, herhangi bir sayfanın tam içeriğini okumadan önce bu verileri bir filtre olarak kullanır. Dolayısıyla başlık, snippet ve URL yapısı, asıl içerikten önce devreye giren birer kapı bekçisidir.
Söz konusu bulguları derinlemesine sorgulamak için Şubat 2025'e ait 1,4 milyon ChatGPT 5.2 promptu (masaüstü) analiz edildi. Araştırma; hangi kaynak türlerinin öne çıktığını, başlık ile sorgu arasındaki semantik uyumun atıf kararını nasıl etkilediğini ve sayfa yaşının bu denklemdeki yerini gözler önüne seriyor.
Tüm Kaynaklar Eşit Yaratılmamıştır: ref_type Hiyerarşisi
ChatGPT içerik alırken her URL'yi ref_type adlı dahili bir alanla etiketler. Bu alan, URL'nin hangi kanaldan geldiğini belirtir. Araştırmada beş farklı kategori tespit edildi: search, news, reddit, youtube ve academia. Bu kategoriler arasındaki atıf oranları çarpıcı biçimde farklılaşmaktadır.
| ref_type | Atıf Oranı | Toplam Veri Noktası |
|---|---|---|
| search | %88,46 | 25.563.589 |
| news | %12,01 | 3.940.537 |
| %1,93 | 16.182.976 | |
| youtube | %0,51 | 953.693 |
| academia | %0,40 | 185.337 |
Kaynak: 1,4 milyon ChatGPT promptu analizi, Şubat 2025 (masaüstü).
Genel search indeksi hem hacim hem de atıf oranı bakımından açık ara öne çıkmaktadır. ChatGPT tarafından atıf kazanan URL'lerin %88'i doğrudan arama sonuçlarından gelmektedir. Bu veriye dayanarak şunu söylemek mümkündür: Yapay zeka aramalarında atıf kazanmak istiyorsanız önce arama sonuçlarında görünür olmanız gerekiyor. Sıralama, AI görünürlüğünün ön koşuludur.
YouTube ve akademik kaynaklar (ör. arXiv.org) büyük hacimde sisteme alınsa da neredeyse hiç atıf kazanamamaktadır. Bunun nedeni kısmen bu kanalların API entegrasyonları aracılığıyla ek akışlar olarak dahil edilmesidir — standart web aramasının üzerine eklenen bir katman. Aynı durum Reddit için de geçerlidir; bu da atıf istatistiklerinin yorumlanmasında dikkate alınması gereken kritik bir ayrıntıdır.
Ortalama olarak ChatGPT her prompt için yaklaşık 16,57 atıf kazanmış URL ve 16,58 atıf kazanamamış URL almaktadır. Ancak atıf kazanamayan URL havuzunun %67,8'i Reddit'ten oluştuğu için ham karşılaştırmalar gerçek tabloyu gizleyebilir. Bu nedenle analizin büyük bölümü ref_type bazında yürütülmüştür.

Atıf Kazanamayan URL'lerin %67,8'i Reddit'ten Geliyor
Araştırmanın en çarpıcı bulgularından biri Reddit'le ilgilidir. Reddit, ChatGPT'nin alım sisteminde kendine özgü bir ref_type'a sahip olup veri setinde 16 milyondan fazla veri noktası üretmiştir. Buna karşın atıf oranı yalnızca %1,93'tür. Daha da çarpıcı olan şudur: Atıf kazanamayan tüm URL'lerin %67,8'i Reddit'ten gelmektedir.
Yani model, konuları anlamak, topluluk uzlaşısını ölçmek ve bağlam oluşturmak için Reddit'i yoğun biçimde kullanmaktadır — ancak nadiren kaynak olarak göstermektedir. Kalabalığın bilgisinden beslenir, sonra kurumsal bir kaynağı öne çıkarır. Bu dinamik, atıf oranlarına ilişkin herhangi bir toplu istatistiği doğrudan etkiler: Reddit'i hesaba katmadan yapılan karşılaştırmalar yanıltıcı sonuçlar üretir.
Atıf Kazanamayan Sayfalarda 3 Kat Fazla Alım Verisi Var — Ama Hikaye Burada Bitmiyor
İlk bakışta verilerin söylediği şey şaşırtıcıydı: Atıf kazanamayan sayfalar, atıf kazananlara kıyasla çok daha fazla dolu alana sahipti. Snippet bulunma oranı atıf kazanamayanlarda %14,81 iken atıf kazananlarda yalnızca %4,36'ydı. Yayın tarihi ise atıf kazanamayanlarda %92,72 oranında mevcutken atıf kazananlarda bu oran %35,98'de kalıyordu.
Ancak bu görüntü bir yanılsamaydı. Derinlemesine incelendiğinde bu tutarsızlığın neredeyse tamamen Reddit'in veri bileşiminden kaynaklandığı anlaşıldı. Reddit içeriği API aracılığıyla çekildiğinde doğası gereği yayın tarihi meta verisi taşır; bu nedenle yüksek pub_date oranı bir Reddit artefaktından ibaretti. Snippet boşluğu ise farklı bir nedene dayanıyordu: Araştırmacı David McSweeney'nin bulgularına göre model, bir URL'yi atıf vermeye karar verdiğinde snippet alanını bırakıp sayfanın tamamını açmaktadır. Bu nedenle atıf kazanan sayfalardaki düşük snippet oranı, bir tercih değil, boru hattının işleyişinden kaynaklanan bir yan üründür.
Analizi yalnızca search ref_type ile sınırlandırıldığında tablo netleşti:
| Search ref_type | Snippet Var mı? | Yayın Tarihi Var mı? | Toplam URL |
|---|---|---|---|
| Atıf kazanan | %2,52 | %33,79 | 22.612.529 |
| Atıf kazanamayan | %0,09 | %49,00 | 2.951.060 |
Search ref_type için izole edilmiş veriler.
Snippet verisi her iki grup için de neredeyse yoktu; dolayısıyla kullanılabilir bir sinyal değil. Yayın tarihi oranları ise birbirine yaklaştı ama atıf kazanamayan sayfalar hâlâ biraz daha fazla yayın tarihi taşıyordu. Dürüst bir değerlendirmeyle: Snippet veya yayın tarihi alanlarının atıf kararındaki rolüne dair bu verilerden güçlü bir sonuç çıkarmak mümkün değildir. Veri bileşimi, gerçek sinyalleri gürültünün altında bırakmaktadır.
Atıf kazanan ile kazanamayan URL'leri karşılaştıran araştırmalar, bu URL'lerin nereden geldiğini hesaba katmadan yürütüldüğünde, veri özelliklerini gerçek kalıplar olarak yanlış yorumlama riskiyle karşı karşıya kalır. Aynı tuzak bu alandaki pek çok çalışmayı etkilemiş olabilir.
Başlıkların Fanout Sorgularıyla Semantik Olarak Uyumlu Olması Gerekiyor
ChatGPT, hangi kaynakların atıf kazanacağını belirlemek için semantik puanlama adı verilen bir süreç kullanır. Model, bir kullanıcının ana sorgusundan hareketle dahili olarak fanout sorguları — yani belirli gerçekleri aramak için ürettiği alt sorular — oluşturur. Atıf için seçim, büyük ölçüde bir sayfanın başlığının bu fanout sorgularıyla ne ölçüde örtüştüğüne bağlıdır.
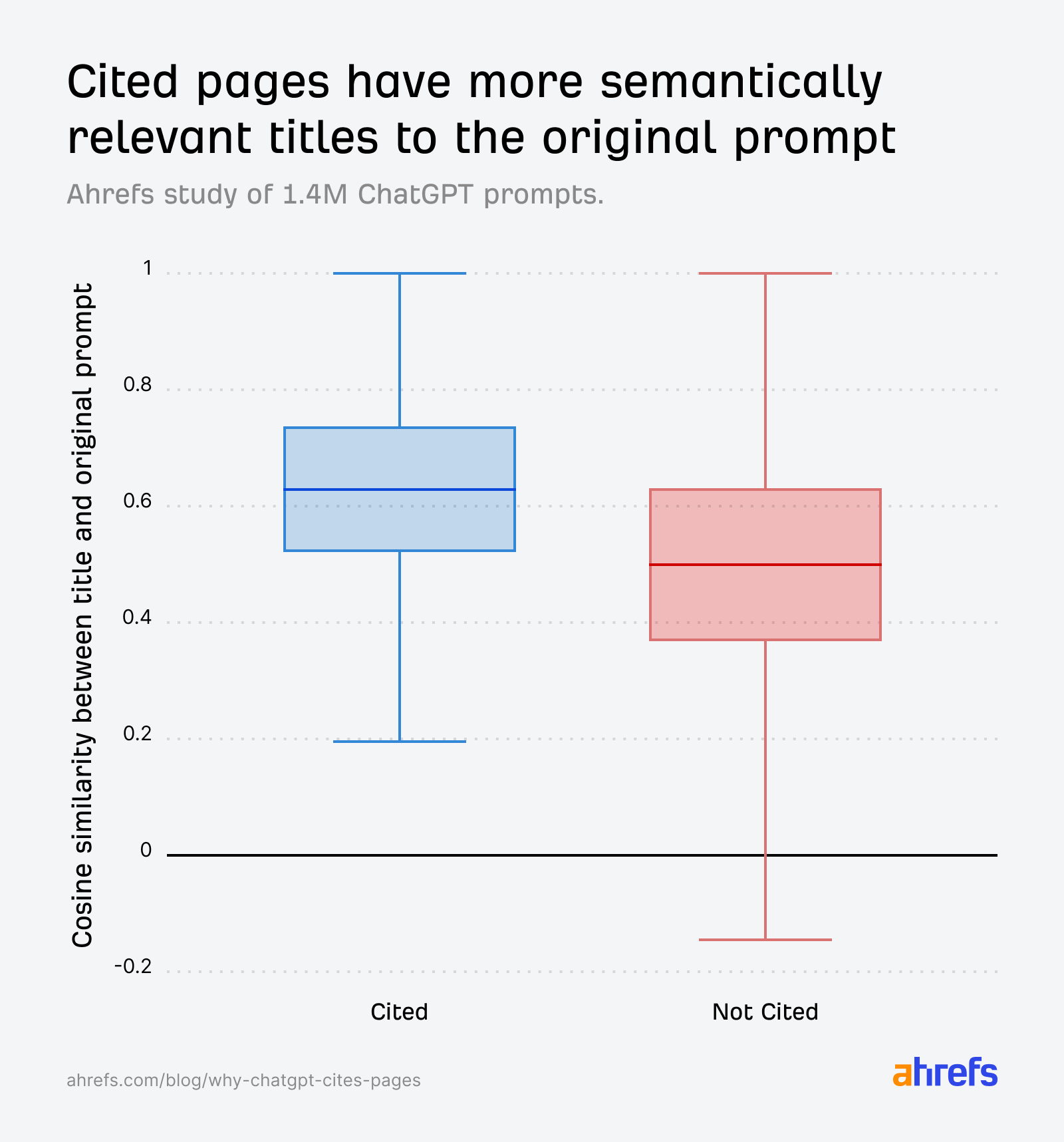
Cosine benzerlik skoru hesaplandığında veriler bunu açıkça ortaya koyuyordu:
- Prompt ile atıf kazanan URL başlığı arasındaki cosine benzerliği: 0,602
- Prompt ile atıf kazanamayan URL başlığı arasındaki cosine benzerliği: 0,484
- Fanout sorgusu ile atıf kazanan URL başlığı arasındaki maksimum eşleşme: 0,656
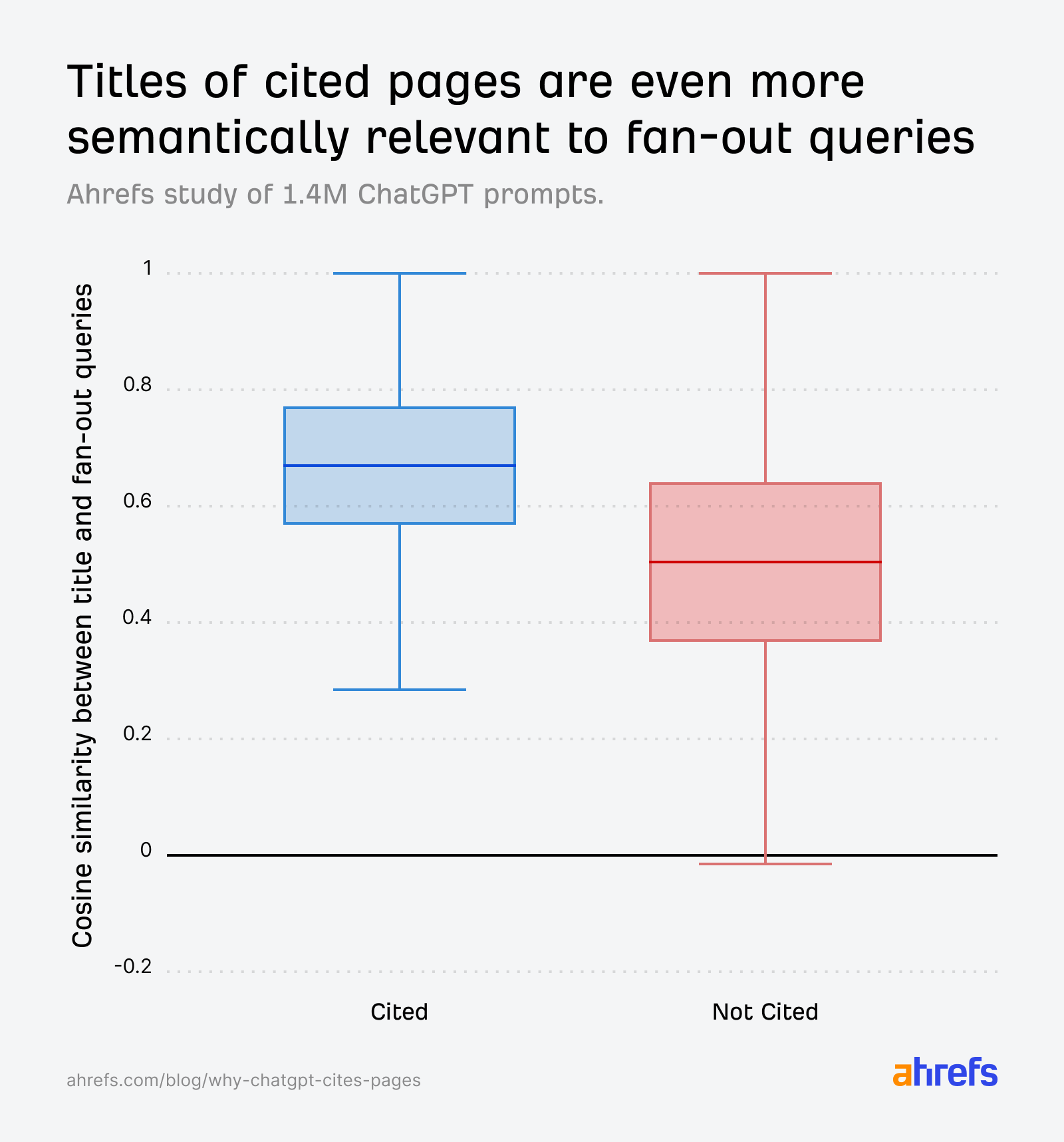
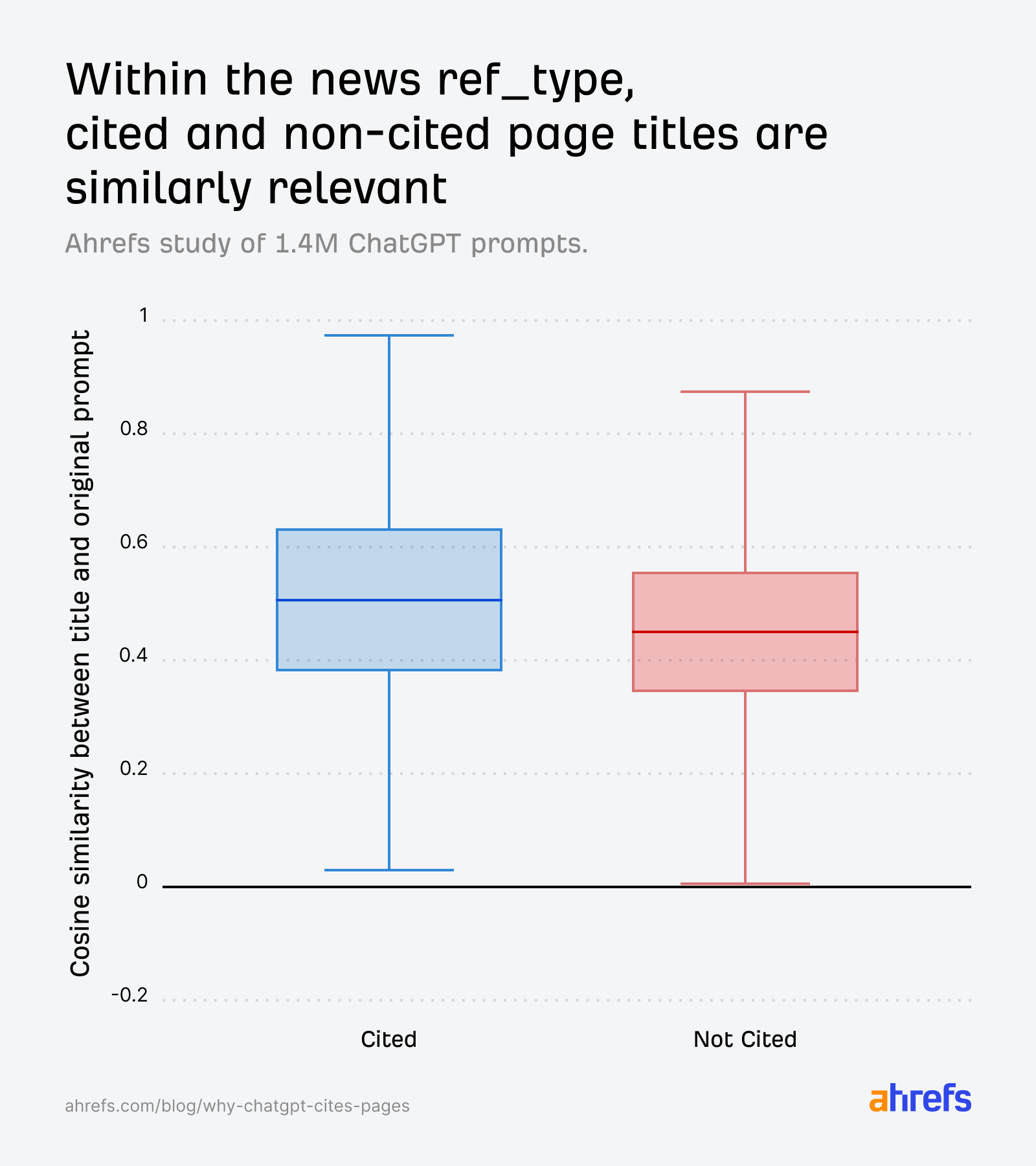
Tüm ref_type kategorilerinde atıf kazanan URL'lerin başlıkları, orijinal promptla tutarlı biçimde daha yüksek benzerlik taşıyordu. Karşılaştırma fanout sorgularına kaydırıldığında bu uçurum daha da belirginleşti; bu da içerik üretiminde ChatGPT'nin arka planda sorduğu alt sorulara odaklanmanın ne denli kritik olduğunu gösterdi.
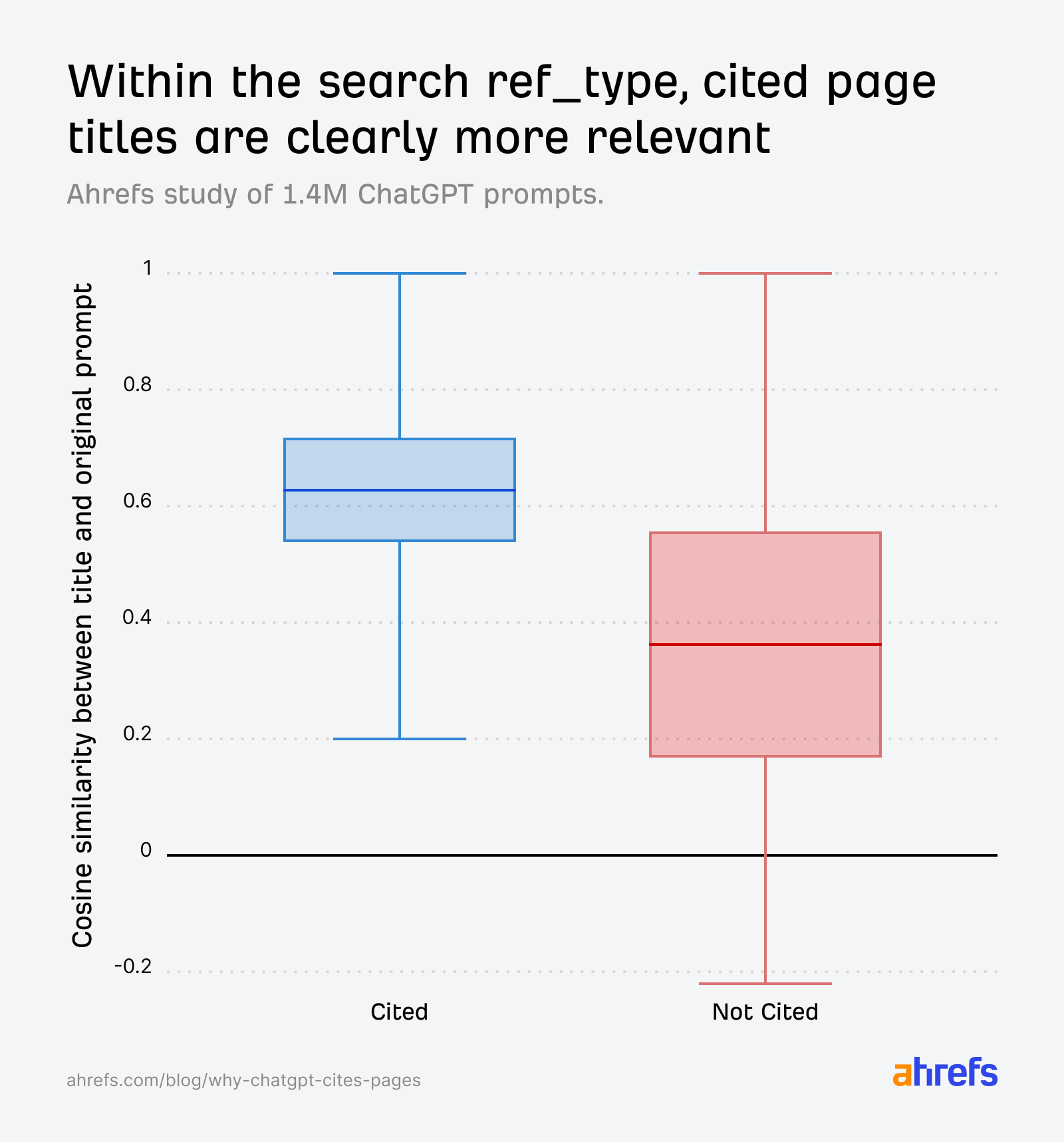
Search ref_type özelinde analiz yapıldığında desen daha da keskinleşti: Atıf kazanan sayfalar açıkça daha iyi uyum sağlarken atıf kazanamayan URL'lerin dağılımı belirgin biçimde düştü. Buna ek olarak, doğal dil URL slug'larına sahip arama sonuçlarının atıf oranı %89,78 iken yapılandırılmamış URL'lerde bu oran %81,11'de kaldı.

URL'niz ve başlığınız, yapay zekanın dahili fanout sorgularıyla semantik olarak uyuşmuyorsa atıf kazanma olasılığınız önemli ölçüde düşer. Başlık optimizasyonu; yalnızca kullanıcıların ne yazdığına değil, modelin arka planda ne sorduğuna göre şekillendirilmelidir.
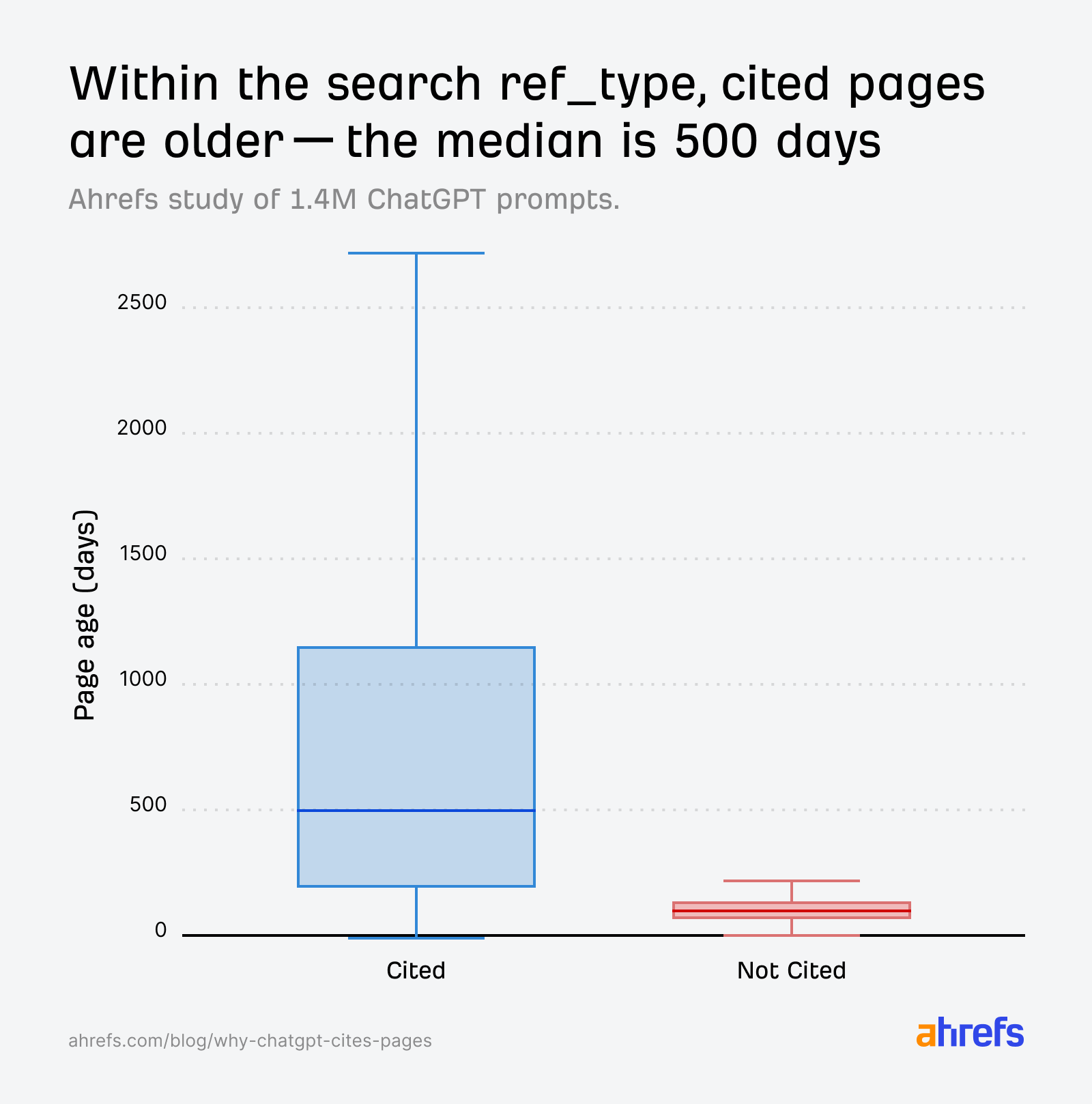
Ortalama Atıf Kazanan Sayfa 500 Günlük — ve Hâlâ Seçiliyor
Taze içeriğin yapay zeka tarafından daha fazla kaynak gösterildiği yaygın bir kanıdır. Daha önceki geniş kapsamlı araştırmalar, ChatGPT'nin Google organik sonuçlarına kıyasla ortalama 458 gün daha yeni URL'lere atıf yaptığını ortaya koymuştu. Ancak bu araştırmanın bulguları bu anlatıya nüans katmaktadır.
Search indeksi incelendiğinde atıf kazanan sayfaların medyan yaşının yaklaşık 500 gün (~1,3 yıl) olduğu görüldü. Bazı atıf kazanan sayfalar 2.700 günü (yaklaşık 7,4 yıl) aşıyordu. Öte yandan daha önceki araştırmanın 958 günlük medyan değeriyle karşılaştırıldığında modelin giderek daha genç sayfalara yöneldiği anlaşılıyordu.
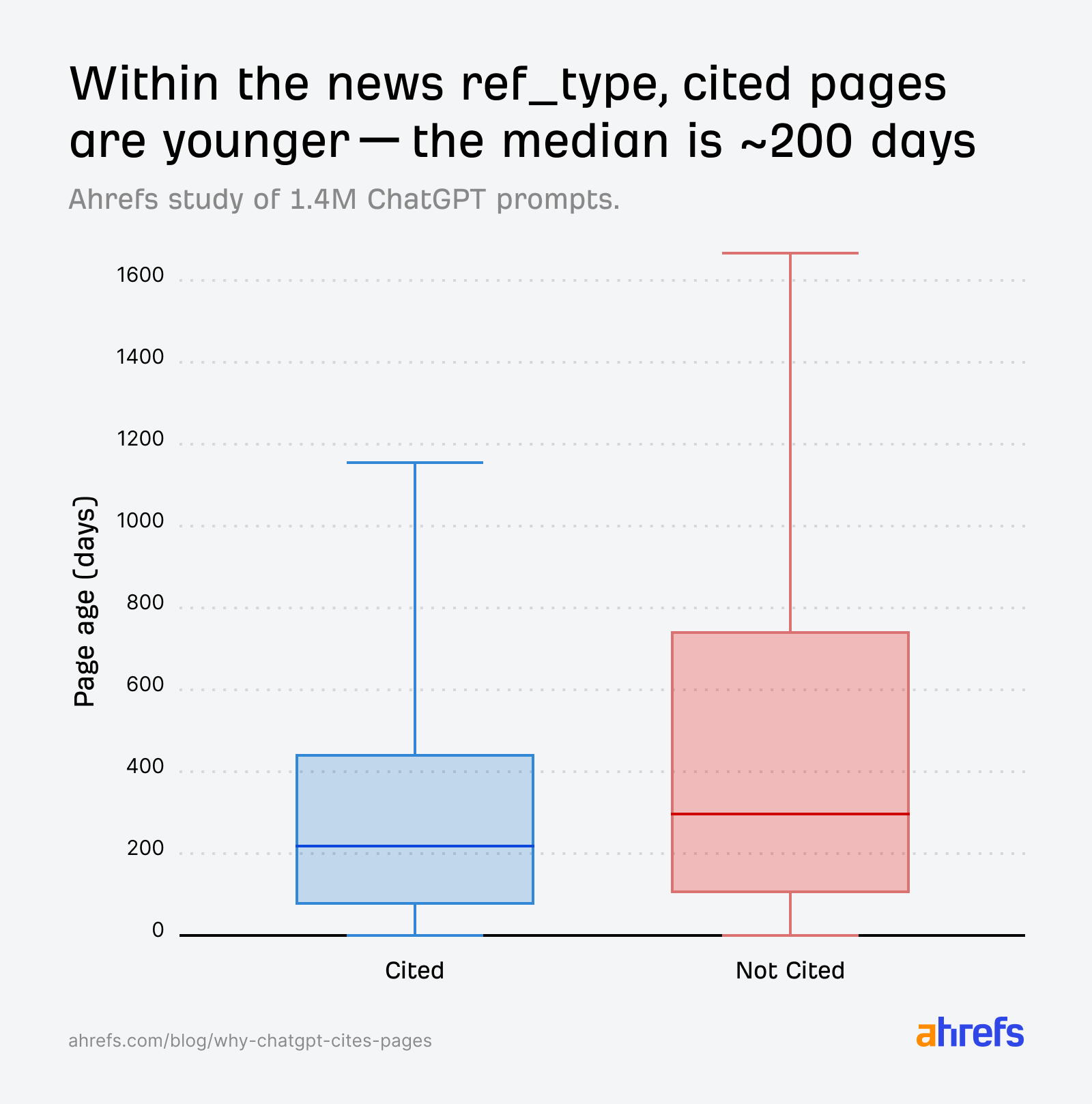
Ancak ilginç olan şu: Atıf kazanamayan sayfalar büyük ölçüde çok genç sayfalardı. Yani tek bir prompt için alım seti içinde bakıldığında, daha yerleşik ve köklü sayfalar atıf kazanırken en taze içerik kenara bırakılıyordu. Görünürde çelişkili olan bu iki bulgu aslında aynı anda doğru olabilir: Geniş popülasyon düzeyinde ChatGPT taze içeriği tercih eder; ama belirli bir alım seti içinde, taze olmanın yanı sıra alakalı olmak daha belirleyicidir. Fanout sorgularıyla uyumlu yeni bir sayfa atıf kazanır; uyumsuz taze bir sayfa ise geri alınır, sonra görmezden gelinir.
News kategorisinde tablo farklılaşıyordu. Atıf kazanan ve kazanamayan sayfalar arasındaki başlık benzerlik skorları neredeyse özdeş çıktığı için model zamansal bir kırıcı uyguluyor ve daha genç sayfalara yöneliyordu.
Atıf Kazanmak İçin Ne Yapmalı?
1,4 milyon prompt üzerinde yürütülen bu analiz, ChatGPT'nin kaynak seçimindeki dinamikleri oldukça net biçimde ortaya koyuyor. Model, genel arama indeksini ön plana çıkarıyor, semantik benzerliği temel bir seçim kriteri olarak kullanıyor ve Reddit'i adını vermekten çekindiği bir başvuru kaynağı gibi değerlendiriyor.
Araştırmanın metodolojik açıdan öğrettiği ders de bir o kadar önemlidir: Atıf kazanamayan URL havuzunun baskın bir kaynak türü tarafından domine edildiği durumlarda, toplu karşılaştırmalar yanıltıcı sonuçlar üretir. Başlangıçta bir paradoks gibi görünen bulgu — daha az optimize edilmiş sayfaların daha fazla atıf kazanması — aslında veri bileşiminin bir yansımasıydı. ref_type bazında izolasyon yapılmasaydı bu hata kolaylıkla bir sonuç olarak sunulabilirdi.
Atıf kazanan sayfaların ortak paydası şudur: Başlıkları ve içerikleri ChatGPT'nin arka planda sorduğu sorularla uyuşmakta ve doğru alım kanalı üzerinden yüzeye çıkmaktadır. Arama sonuçlarında yer almadan AI görünürlüğü kazanmak son derece güçtür; bu nedenle organik sıralama ile AI atıf stratejisi birbirinden ayrı düşünülmemelidir.
Pratik çıkarımlar şöyle özetlenebilir:
- Başlık optimizasyonu: Yalnızca kullanıcı sorgusuna değil, modelin ürettiği fanout alt sorgularına da odaklanın.
- Doğal dil URL yapısı: Temiz, anlamlı slug'lar atıf oranını yaklaşık 9 puan artırmaktadır.
- Arama görünürlüğü önce gelir: Atıf kazanan URL'lerin %88'i search ref_type'tan gelmektedir; önce sıralamaya girin.
- Taze olmak tek başına yeterli değildir: Yeni bir sayfa fanout sorgularıyla uyuşmuyorsa alım gerçekleşir, atıf gerçekleşmez.
- Haber içeriğinde hız kritiktir: News kategorisinde benzerlik skorları eşitlendiğinde model yaşa göre seçim yapar — ilk yayınlayan öne çıkar.

Oktay Çomak
Kurucu & SEO Stratejisti, SEOART
Kurumsal SEO'da veri disiplini ve ölçülebilir iş etkisine odaklanıyoruz; yol haritanızı birlikte netleştirelim.
LinkedInSEO yol haritanızı birlikte çizelim
Teknik sağlık, içerik uyumu ve görünürlük için ücretsiz ön analiz talep edin; öncelikli bulgularla sonraki adımları konuşalım.