1.885 Sayfada JSON-LD: Yapay Zekâ Alıntıları Neden Firlamadı?
Altı milyon URL ön taramasında alıntılı sayfalarda JSON-LD yaklaşık üç kat daha sık; 1.885 işlem ve 4.000 kontrolle DiD. AI Özetleri %4,6 ve ~2.500’de bir anlamlılık, AI Modu ve ChatGPT’te sıfırdan ayırt edilemez fark; dört test, sınırlamalar ve canlı çekim bulgusu — GEO için gerçekçi çerçeve.

Editör notu
Bu yazıda JSON-LD ile yapay zekâ alıntıları arasındaki ilişkinin, büyük örneklemde eşlenmiş kontrol ve difference-in-differences (DiD) yöntemiyle nasıl ölçüldüğünü sade Türkçe ile özetliyoruz. Özet tablolar ve görseller bu ölçüm çerçevesine dayanır; yorum ve uygulama önerileri SEOART editoryal çizgisindedir. Kendi sitenizde uygularken Open Graph, canonical ve GEO stratejisi bileşenlerini birlikte düşünün.
Yaklaşık altı milyon URL üzerinde yapılan ön taramada, yapay zekâ tarafından alıntılanan sayfalarda JSON-LD bulunma olasılığı, alıntılanmayanlara göre yaklaşık üç kat daha fazladır. Bu güçlü korelasyon LinkedIn slaytlarında hızla paylaşılır ve AI Özetleri dünyasında yapılandırılmış veriyi “tek başına çözüm” gibi okutmaya elverişlidir — oysa korelasyon tek başına nedensellik değildir.
- ~6MURL ile ön tarama (korelasyon tabanı)
- ≥100Şubat 2025’te en az 100 AI Özeti alıntısı (örneklem eşiği)
- 1.885JSON-LD eklenen sayfa (izlenen küme)
- 4.000Eşlenmiş kontrol URL’si
- DiDDifference-in-differences (DiD), platform trendinden arındırma
- 30 günÖnce / sonra penceresi
- Ağu ’25–Mar ’26Çalışma ve raporlama penceresi
Sorun şu: yüksek korelasyon, tek başına nedensellik değildir. Şema ekleyen siteler çoğunlukla teknik SEO’ya yatırım yapan, güçlü içerik üreten ve otorite inşa eden sitelerdir; alıntı sinyali bu paketle birlikte gelir. Bu yüzden ikinci bir tasarımla — yalnızca şema eklenmesinin etkisini ölçen bir çalışmayla — “sayfama application/ld+json eklersem alıntı artar mı?” sorusuna yaklaşıyoruz.
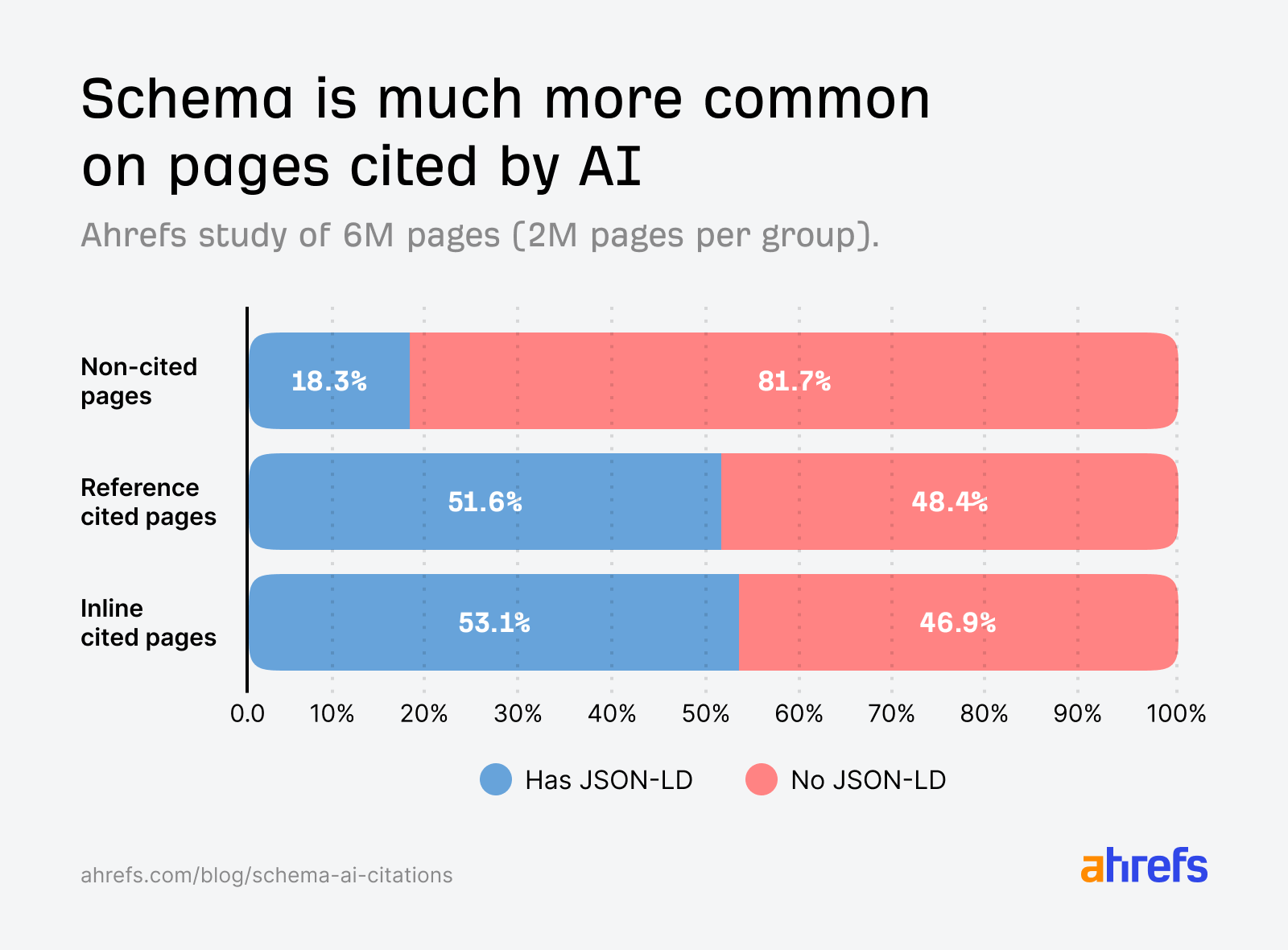
Üstte: Geniş örneklemde alıntılı ve alıntısız URL’ler arasında yapılandırılmış veri kullanımı farkı (özet görsel).
JSON-LD eklemek, üç yapay zekâ yüzeyinde de alıntıyı sıçratmadı
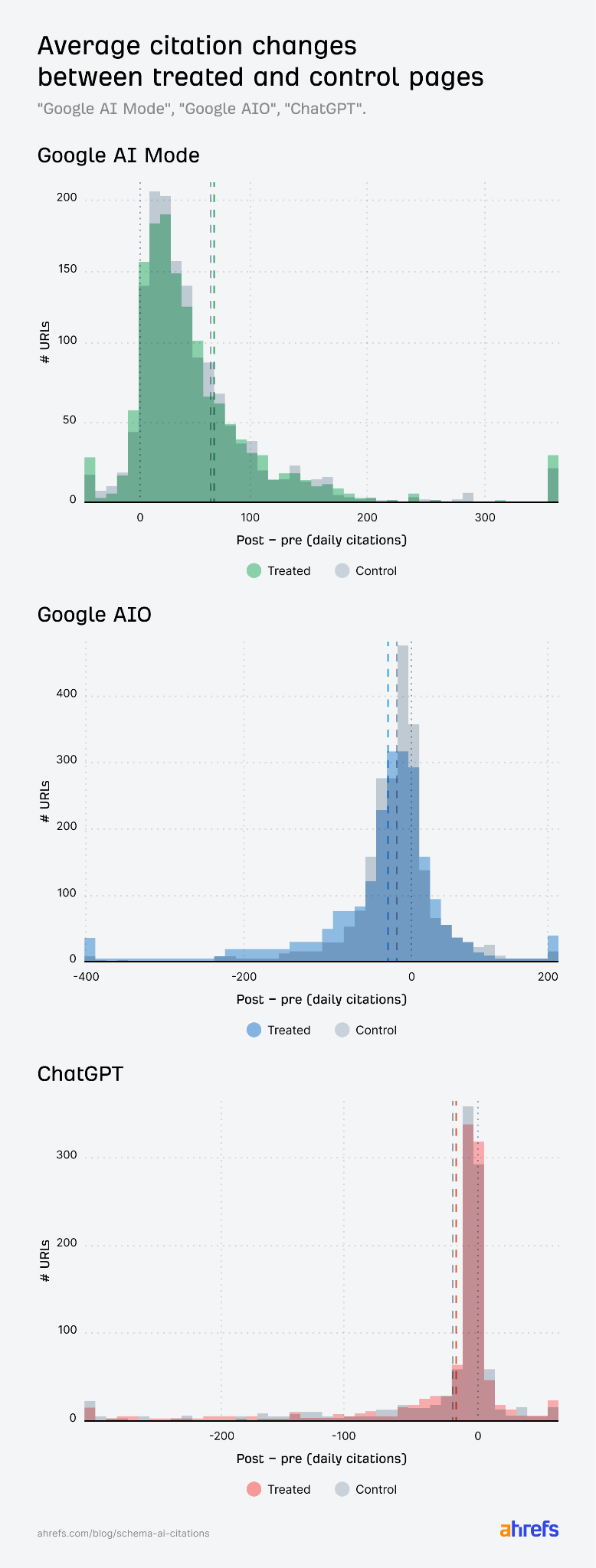
Çalışma penceresi Ağustos 2025 – Mart 2026 iken, bu süreçte JSON-LD ekleyen 1.885 sayfa, benzer ön dönem alıntı profiline sahip 4.000 kontrol URL’si ile eşleştirildi; Google AI Özetleri, Google AI Modu ve ChatGPT üzerindeki alıntı değişimi raporlandı. Sonuç: belirgin bir “şema bonusu” görülmüyor; AI Modu ve ChatGPT’teki küçük farklar istatistiksel olarak sıfırdan ayırt edilemez düzeydedir.
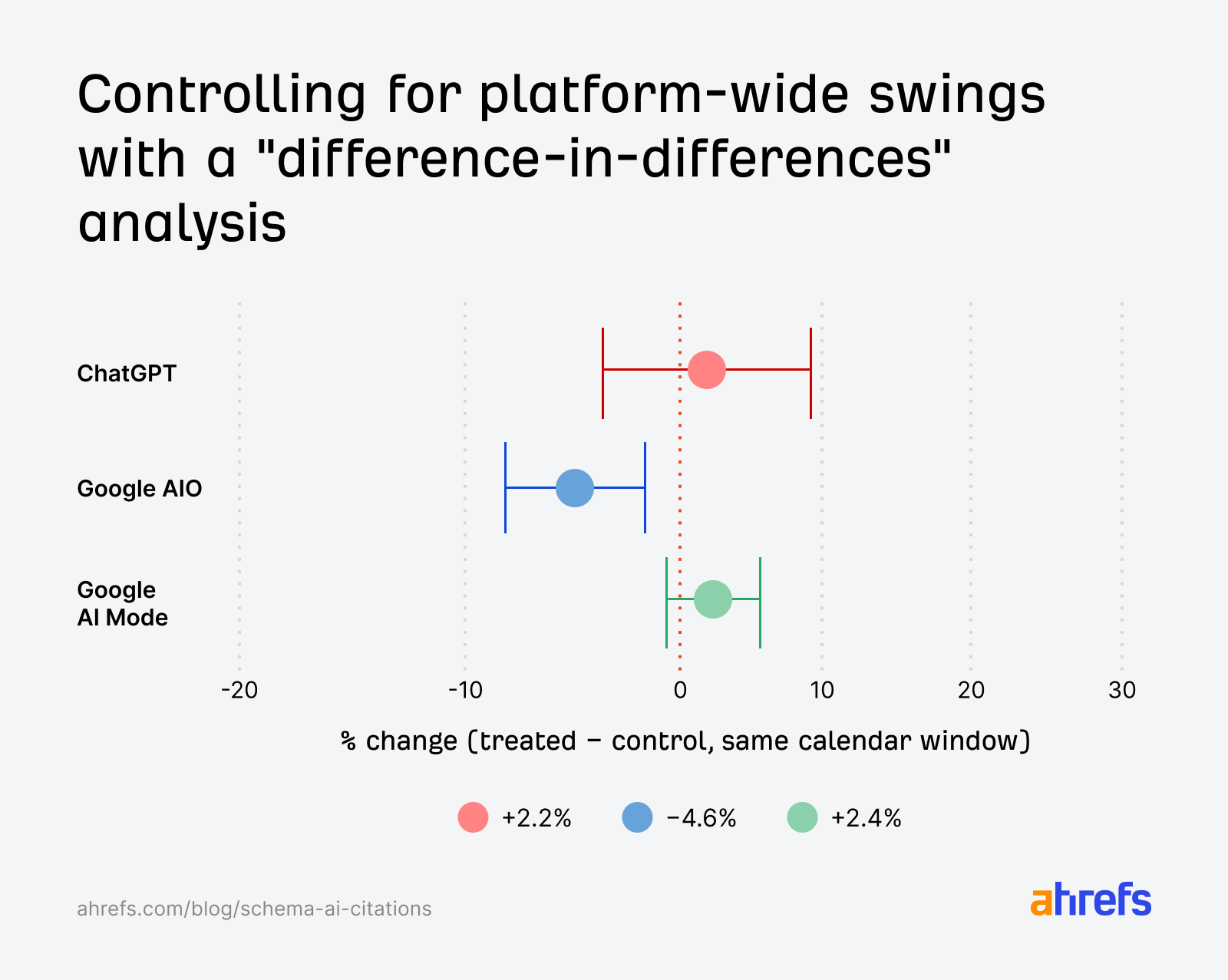
| Yapay zekâ kaynağı | Göreli alıntı etkisi | Yorum |
|---|---|---|
| Google AI Özetleri | −%4,6 | Kontrollere kıyasla küçük ama anlamlı düşüş; %4,6’lık ek gerilemenin şansa bağlı görülme olasılığı kabaca 2.500’de bir düzeyindedir. Her iki grup da zaten negatif trenddeydi. |
| Google AI Modu | +%2,4 | İstatistiksel olarak sıfırdan ayırt edilemez; güven aralığı geniş, platform gürültüsüyle karışabilir. |
| ChatGPT | +%2,2 | İstatistiksel olarak sıfırdan ayırt edilemez; küçük pozitif rakam, anlamlı bir kazanç iddiası taşımaz. |
Yüzdeler, eşlenmiş difference-in-differences (DiD) çerçevesindeki ana tahmini ifade eder; mutlak alıntı sayıları sayfa bazında yüzlerle ifade edilen örneklemde yorumlanmıştır.
Metod notu
Difference-in-differences (DiD) yaklaşımı, “herkese birden yükselen platform trendi”ni şema etkisinden ayırmak için kullanılır. Böylece yalnızca “önce / sonra” kıyasının sık düştüğü tuzak — genel AI trafiği patlarken her şeyi şemaya yazmak — azaltılır.
AI Özetleri tarafında %4,6’lık düşüşü nasıl okumalıyız?
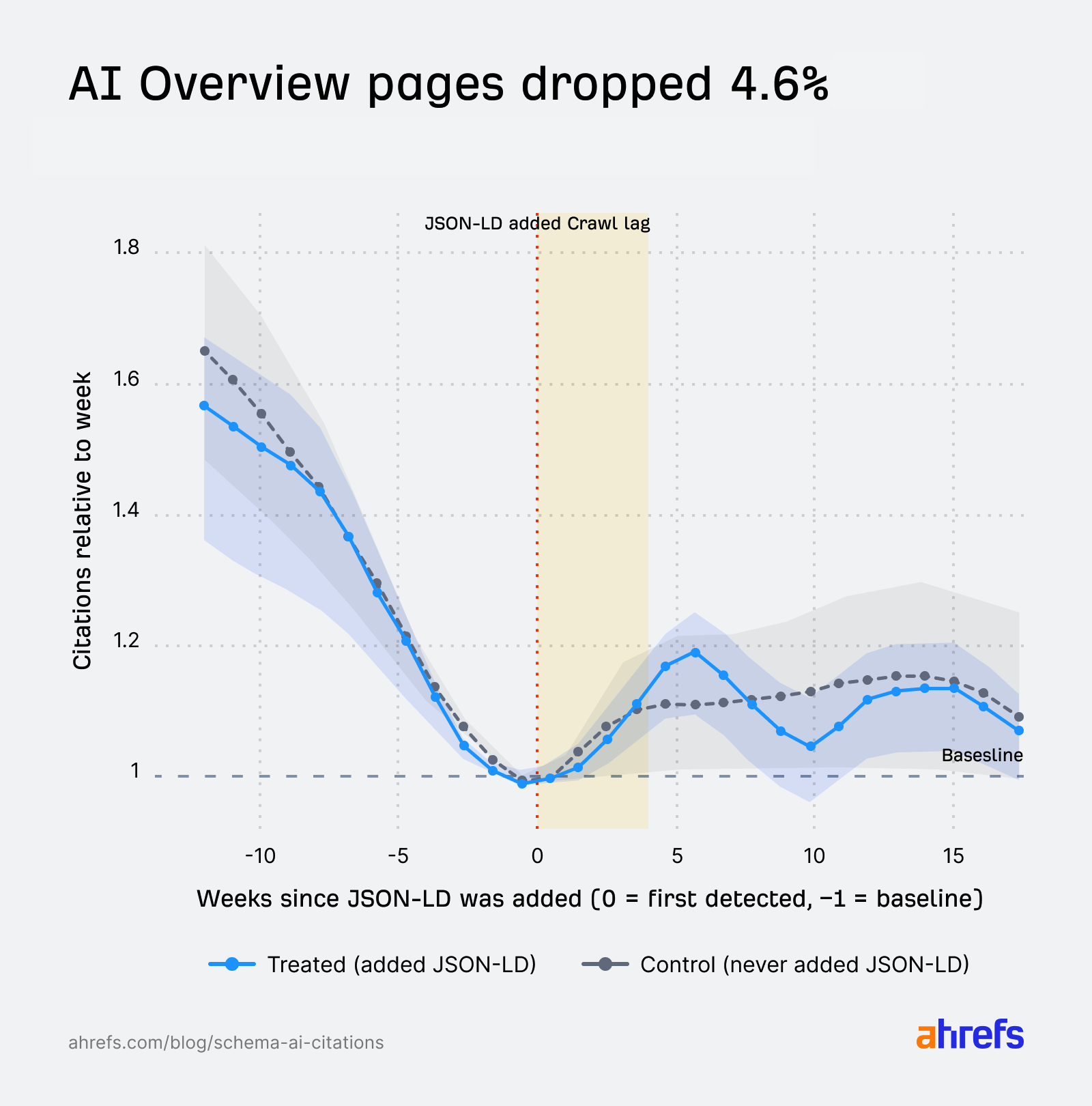
AI Özetleri’nde işlem gören sayfaların kontrollere göre yaklaşık %4,6 daha fazla gerilemesi istatistiksel olarak anlamlı görünür; tahmin edilen farkın yalnızca şansa bağlı oluşma olasılığı kabaca 2.500’de bir düzeyindedir. Buna rağmen yorumu iki uyarıyla birlikte yapmak gerekir:
- Mutlak etki küçüktür. Örneklemde çoğu sayfa günde yüzlerce alıntı aldığı için, ortalama etki sayfa başına günde yaklaşık 12 alıntı kaybı düzeyindedir — yani istatistiksel olarak “gürültüden sıyrılan” bir fark olsa da operasyonel olarak küçük bir sapmadır.
- Her iki grup da şema eklenmeden önce zaten düşüşteydi. Bu, Google’ın belirli içerik türlerini özetlerde daha az göstermesi, içeriğin tazelenmemesi veya tarama gecikmesi gibi şemadan bağımsız nedenlerle uyumludur.
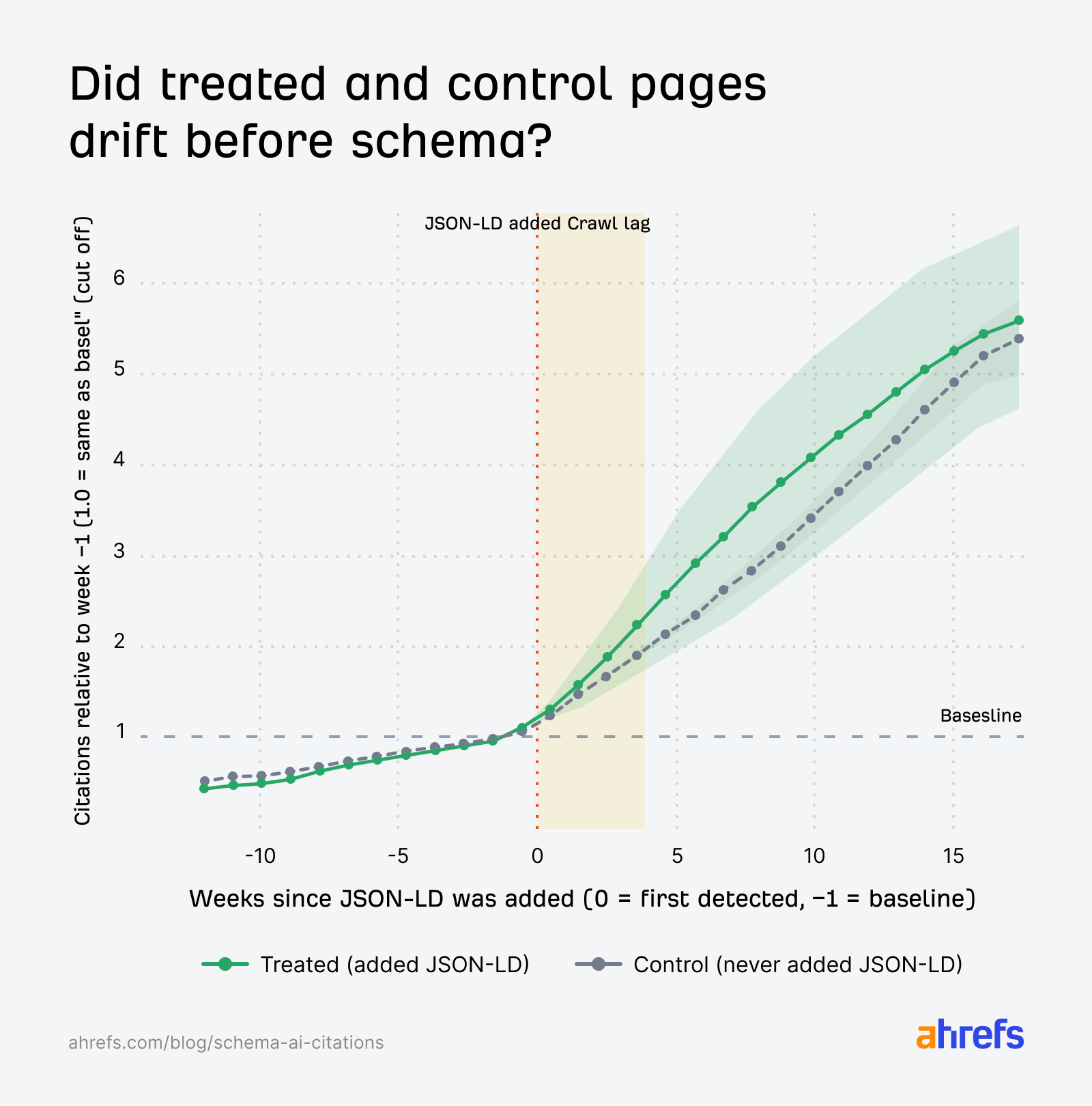
Grafiği okuma
Her iki çizgi de “işlem haftasından bir önceki hafta” 1,0’a sabitlenir; böylece başlangıç noktası tasarım gereği aynıdır. Önemli olan eğrinin şekli ve işlemden sonra iki grubun birbirinden ne kadar ayrıldığıdır.
Özetle: bu veri setinde şemanın AI Özetleri’nde “gizli bir süper güç” olduğuna dair kanıt yok; küçük negatif sapmanın nedeni tek başına izole edilememiştir ve başka faktörlerle de açıklanabilir — tek başına “şema zarar verir” demek için yeterli değildir.
Şema etkisini izole etmek için ne yaptık?

Önce geniş URL havuzunda <script type="application/ld+json"> etiketinin yokken → varken geçtiği tarih tespit edilir. Bu tarih, çalışmanın işlem (treatment) günü kabul edilir. Ardından her hedef URL için, farklı kök alanlardan seçilmiş ve işlem öncesi alıntı seviyesi benzer olan üç kontrol URL’si eşlenir; kontrollerde JSON-LD eklenmemiştir.
- Tarayıcı veritabanında JSON-LD’nin son görülmediği gün
- Aynı sayfada JSON-LD’nin ilk görüldüğü gün
Alıntılar, işlem tarihinden önceki ve sonraki 30 günlük pencerelerde toplanır. Böylece “aynı başlangıç hızında giden” iki grup kıyaslanır; tek fark, bir grubun şema eklemesidir. Ölçümün güven sınırları için ayrıca Çalışmanın sınırları bölümüne bakın.
Dört ayrı test, aynı hikâyeyi anlatıyor
Test 1: İki örneklem t testi
İşlem ve kontrol gruplarının, işlem öncesi ve sonrası dönemlerdeki ortalama alıntı değişimini birbirine kıyaslar; hızlı bir “gruplar farklı mı?” kontrolüdür.
Test 2: Difference-in-differences (DiD)
Panel verisinde platform genelindeki trendi ayıklayarak şema eklemenin ana nedensel okumaya en yakın tahminini üretir; metnin özet tablosu bu çerçeveye dayanır.
Test 3: Olay çalışması (event study)
Haftalık eğriler üzerinden işlem tarihinden önce iki grubun zaten ayrışıp ayrışmadığını kontrol eder; paralel trend varsayımına dair görsel teyit sağlar.
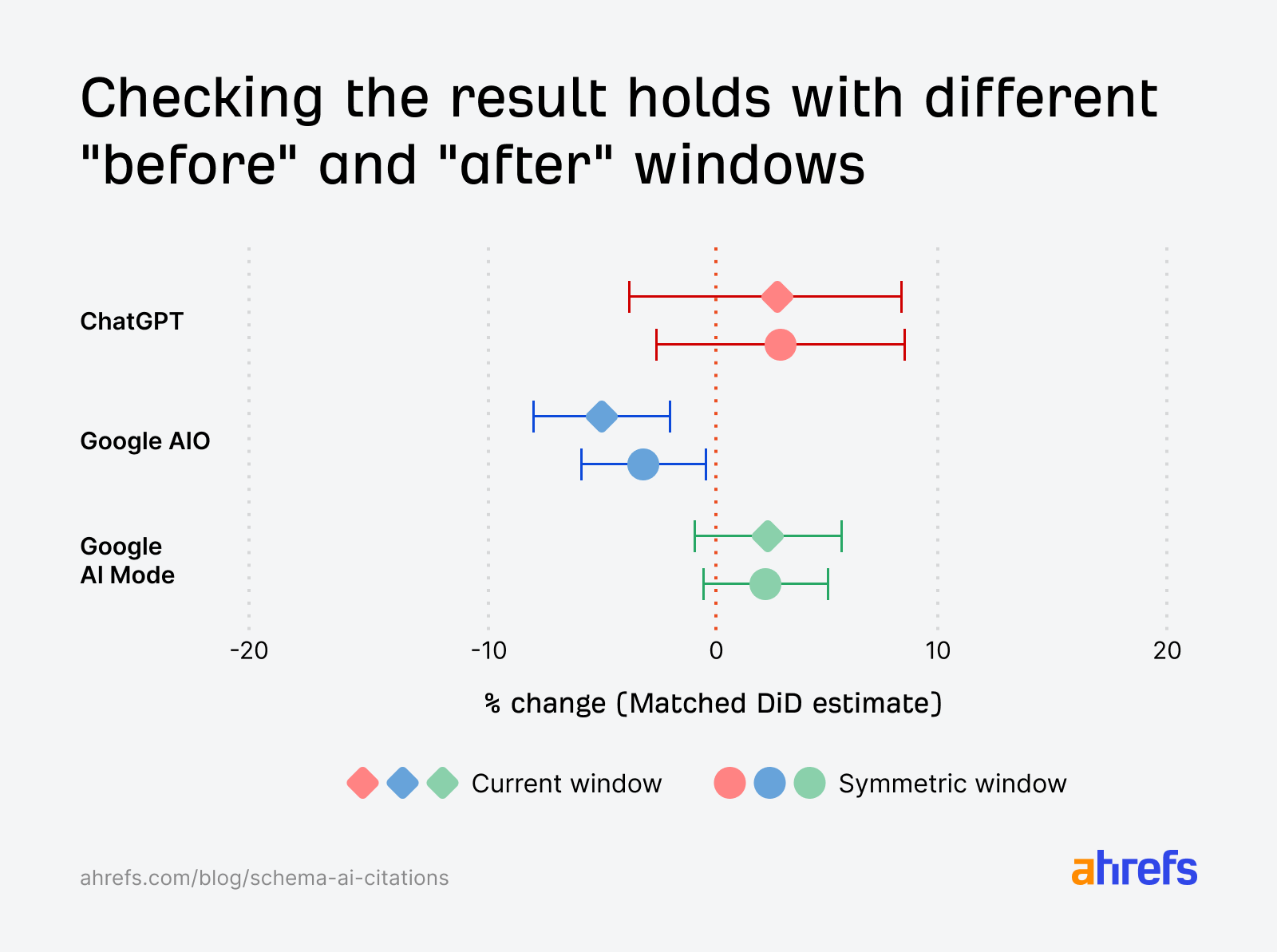
Test 4: Simetrik pencere ile DiD tekrarı
“Önce / sonra” gün sayısı ve pencere tanımı değiştirildiğinde tahminlerin ne kadar stabil kaldığını test eder; tek bir tarih seçimine takılı kalmadığınızı doğrular.
Bu dört test birlikte aynı yönde sonuç verir: AI Modu ve ChatGPT’te belirgin kazanç yok; AI Özetleri’nde hafif negatif fark var ve yorumu dikkatli yapmak gerekir.
AI Modu patlaması
Ham “önce / sonra” büyümesi çok yüksek görünebilir; fakat kontrol grubu da benzer şekilde yükseldiğinde, asıl hikâye platform genelindeki genişlemedir. DiD bu tabanı sıyırır ve kalan şema etkisi birkaç puanlık bantta kalır.
Çalışmanın sınırları
Aşağıdaki maddeler, bulguları aşırı genellemeden önce göz önünde bulundurulmalıdır:
- Eşzamanlı değişiklikler. Şema eklenirken aynı sprintte başlık, iç bağlantı, hız veya içerik güncellemesi yapmak yaygındır; şema etkisini tam izole etmek zordur.
- Şema türleri birleştirildi. Article, FAQPage, Product, HowTo, Organization vb. türler tek havuzda toplandı; hangi türün alıntıya daha fazla etki ettiği bu analizde ayrıştırılmadı.
- Kısa pencere. Ölçüm 30 günlük önce / sonra ile sınırlıdır; 60–90 günlük daha uzun pencereler yavaş etkiyi ortaya çıkarabilir, burada test edilmedi.
- Yalnızca JSON-LD. Microdata ve RDFa bu nedensel okumada işlenmedi.
- Yalnızca HTML içindeki şema. JavaScript ile sonradan enjekte edilen yapılandırılmış veri ölçüme dahil değildir; yapay zekâ tarayıcılarının ikisini farklı ele aldığı senaryolar dışarıda kaldı.
- AI Özetleri’ndeki %4,6’lık ek gerilemenin tek nedeni hâlâ net açıklanamamıştır; alternatif açıklamalar (özet politikası, içerik türü, rekabet) masada kalmaya devam eder.
Zaten yoğun alıntı alan sayfalar üzerinde çalışıldı
Veri kümesindeki her sayfa, Şubat 2025’te en az 100 AI Özeti alıntısı almış kümeye dahil edilmiştir. Yani “hiç görülmeyen” URL’ler değil; keşif aşamasını aşmış içerikler. Bu tasarım, “şema ekleyince sıçrama olur mu?” sorusunu zaten seçilmiş adaylar üzerinde test eder — henüz alıntı almayan sayfalar için sonuç farklı olabilir (ve bu çalışma o soruyu doğrudan yanıtlamaz).
Üçüncü taraf bir deney özetinde (searchVIU), ChatGPT, Claude, Perplexity, Gemini ve Google AI Modu’nun beşi de canlı sayfa çekiminde yalnızca görünür HTML içeriğini çıkarmış; JSON-LD ile gizlenmiş Microdata ve RDFa tamamen yok sayılmıştır. Bu, “şema her zaman modelin gözüne girer” varsayımını zayıflatır; üretim ortamında render ve engelleme politikalarını kendi takip aracınız veya sayfa kaynağı testleriyle ayrıca doğrulamak gerekir.
Kendi sitenizde nasıl küçük bir doğrulama koşusu kurarsınız?
Düşük maliyetli bir doğrulama için şu sırayı izleyin; alıntı metriklerini Search Console, sıralama takibi veya kurumsal GEO panonuzdaki kendi izleme aracınızla kaydedin (markaya özel ürün adına ihtiyaç yoktur):
- Test sayfalarını seçin: Geçmişte en az düşük düzeyde de olsa alıntı görmüş URL’ler — sıfır alıntıda “şema işe yaramadı” ile “zaten görünmüyordu”yı ayırmak zorlaşır.
- Kontrol sayfalarını seçin: Benzer alıntı profiline sahip olsunlar; şema eklemeyin.
- Taban metriğini kaydedin: Aynı gün damgasıyla Google AI Özetleri, Google AI Modu ve ChatGPT üzerindeki alıntı veya görünürlük göstergelerinizi not edin.
- Yalnızca şema ekleyin: JSON-LD’yi yerleştirin, işlem tarihini damgalayın; test süresince içerik, iç bağlantı ve teknik değişiklik yapmayın.
- 30 gün veya daha sonra kıyaslayın: İki grubun göreli kazancına bakın — “ikisi de aynı oranda mı yükseldi?” sorusu platform trendini ayıklar.
- İsterseniz 60 güne uzatılmış ikinci bir okuma ekleyin; yavaş etkiler ilk pencerede görünmeyebilir.
- JSON-LD türünü (Article, FAQ, Product vb.) not edin; gelecekte tür bazlı ayrıştırma için veri biriktirirsiniz.
Operasyonel ipucu
Şema doğrulamasını Search Console zengin sonuç testleri ve sayfa kaynağı incelemesiyle çiftler; Google Search Console kapsamı ile birlikte izleyin.
Alıntılı sayfaların çoğunda şema var — bu neyi kanıtlamaz?
Ön tarama verisinde yapay zekâ tarafından alıntılanan sayfaların yaklaşık %53’ünde şema (JSON-LD) bulunuyor — ancak bu oran, şemanın alıntıyı sağladığını kanıtlamaz; tersine, güçlü sitelerin hem şema kullanması hem de seçilmesi olasıdır. Otorite, teknik olgunluk ve içerik kalitesi yüksek olan siteler hem yapılandırılmış veriyi tercih eder hem de yapay zekâ sistemlerince daha sık seçilir; şemayı çıkardığınızda bile güçlü sinyaller devam edebilir.
Zaten alıntı alan sayfalarda yalnızca JSON-LD ekleyerek alıntı artışı beklemek bu verilerle desteklenmiyor. Buna karşılık şema; zengin sonuçlar, sesli asistanlar, bilgi grafiği, varlık tanıma ve klasik aramada snippet netliği için hâlâ değerlidir — yalnızca onu “yapay zekâ alıntısı sihirli değneği” olarak konumlandırmayın. Strateji: yapılandırılmış veriyi SEO–AEO–GEO üçlüsünde teknik disiplin öğesi olarak görün.
Özet uyarı
Yapay zekâ alıntısı hedefliyorsanız öncelik; benzersiz bilgi değeri, güvenilir kaynak göstergeleri, güçlü iç bağlantı ve ölçülebilir teknik sağlıktır. JSON-LD bunların yerine geçmez; doğru kurulduğunda ise yanlış anlaşılmayı azaltan bir katman sağlar.

Oktay Çomak
Kurucu & SEO Stratejisti, SEOART
Kurumsal SEO'da veri disiplini ve ölçülebilir iş etkisine odaklanıyoruz; yol haritanızı birlikte netleştirelim.
LinkedInSEO yol haritanızı birlikte çizelim
Teknik sağlık, içerik uyumu ve görünürlük için ücretsiz ön analiz talep edin; öncelikli bulgularla sonraki adımları konuşalım.