ChatGPT Neden Bir Sayfayı Diğerine Göre Daha Çok Alıntılıyor? 1,4 Milyon İstem Çalışması
ChatGPT neden topladığı URL’lerin yalnızca yarısını alıntılıyor? 1,4M istem, ref_type (search, news, reddit, youtube, academia), Reddit boşluğu, fan-out sorguları, kosinüs benzerliği ve sayfa yaşı — tablolar ve 13 görselle bağımsız Türkçe özet; GEO ve alıntı stratejisi.

Bağımsız uyarlama
Aşağıdaki özet, Ahrefs’in Nisan 2026 tarihli çalışmasına dayanır; tablolar, grafikler ve ekran görüntüleri aynı kaynaktan alınmış, metin ve çıkarımlar SEOART editoryal disiplininde yeniden ifade edilmiştir. Harici GEO kavramı için bkz. GEO hizmeti sayfamız.
ChatGPT yanıtlarındaki numaralı mavi bağlantıları artık çoğumuz ezbere biliyoruz: bunlar, modelin dış bilgiye dayandırdığı alıntılardır. Araştırmaya göre model tek bir sorgu için onlarca URL toplasa da, son yanıtta bunların yalnızca kabaca yarısını açıkça alıntılıyor.
- ~%50Alıntı oranı (URL bazında)
- 1,4MChatGPT 5.2 istemi (şub. 2025, masaüstü)
- 5ref_type kanalı
- fan-outAlt sorgu eşleşmesi
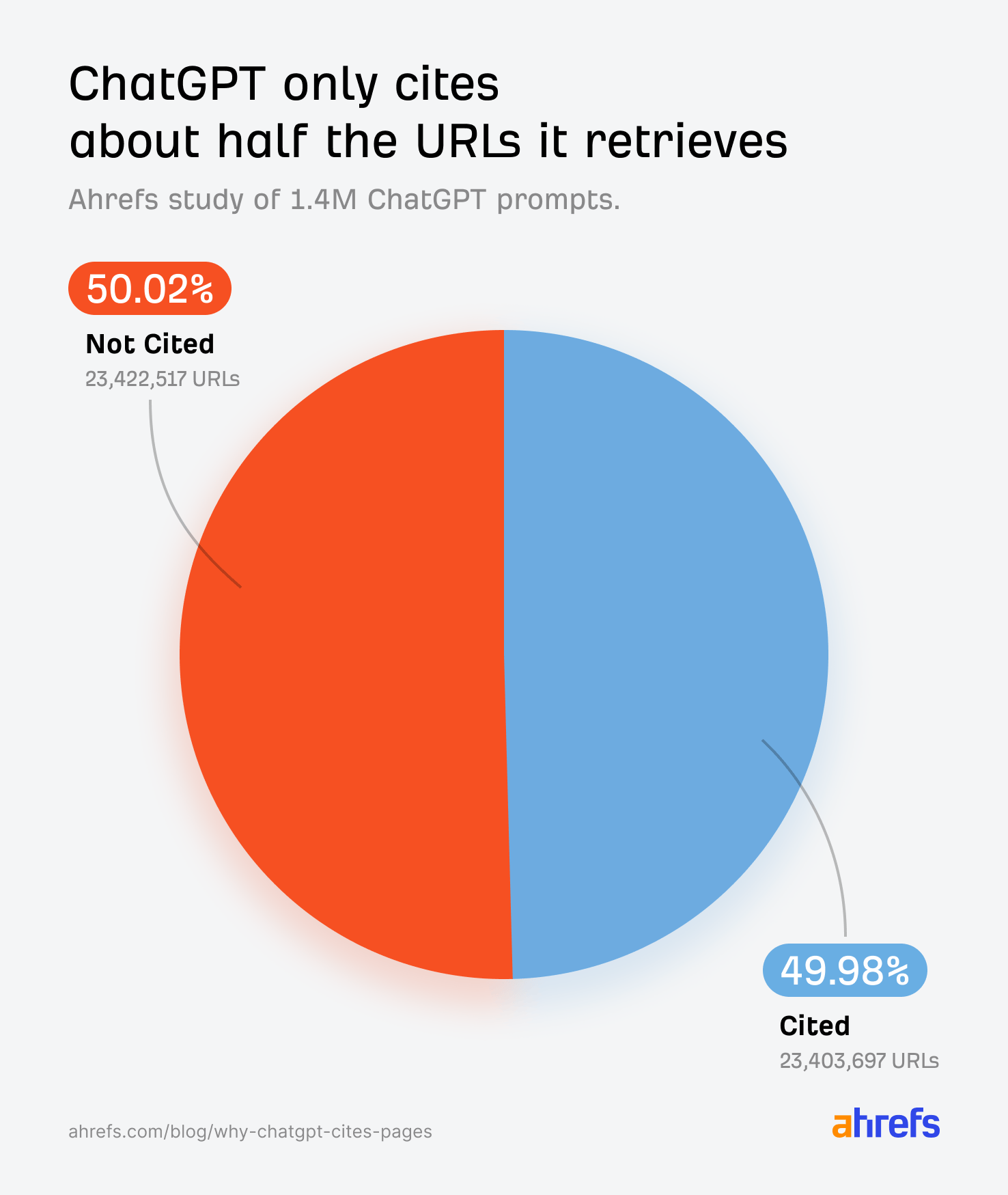
Üstte: Kaynak çalışmadan — toplanan ve alıntılanan URL hacimleri (yaklaşık 23,4M alıntı satırı; dilim oranı %50’ye yakın).
Peki neden biri alıntı alırken, açıkça toplanmış başka bir sayfa hiç görünmez?
Dan Petrovic’in incelemelerine göre ChatGPT bir sonuç getirdiğinde genelde başlık, kısa özet/snippet, URL ve bir kimlik numarası birlikte döner. Model, sayfanın tamamını açmadan önce bu meta veriyi “ön eleme” için kullanır.

Özet: Gerçek içerikten önce, başlık, snippet ve URL ilk kararda ağır yükü taşır; bu da ChatGPT’nin webden bilgi toplama hattıyla birlikte düşünülmelidir.
Not — tam tarama mı, meta mı?
Veri setindeki tüm URL’ler, ChatGPT’nin toplama (retrieval) boru hattında döndü; bu, her satırın kelimesi kelimesine tam metin okunduğu anlamına gelmeyebilir. Dış araştırmalara göre aday değerlendirmesinde çoğunlukla başlık, URL ve snippet gibi alanlar kullanılır; yalnızca seçilenler tam sayfa açılır. Bu yüzden %50 oranı, “okunduktan sonraki karar” değil, uçtan uca yolculuğun toplam görüntüsünü yansıtır.
Çalışmanın merkezindeki soru şu: Alıntıyı gerçekten ne yönlendiriyor? Sorgu ile toplanan meta alan arasındaki anlamsal benzerlik mi artıyor, hangi alanlar ağırlık taşıyor, okunaklı URL yolları belirsiz olanlara göre üstün mü? Ahrefs, Şubat 2025 dönemine ait 1,4 milyon ChatGPT 5.2 istemini incelemiş; istatistik Xibeijia Guan eşliğinde üretilmiştir. Önce toplama kanallarını anlamak gerekir: her URL aynı “kapıdan” girmiyor.
Kaynak kanalları eşit değil: ref_type ayrımı
Toplanan her sonuç, dahili ref_type alanı ile etiketlenir; bu, sonucun hangi kanaldan (ör. genel arama, haber, Reddit API beslemesi) geldiğini sınıflar.
Beş sınıf: search, news, reddit, youtube, academia. Alıntı oranları (ve hacimler) birbirinden zıt seyreder.
| ref_type | Alıntı % | Veri noktası (toplam) |
|---|---|---|
| search | 88,46 % | 25.563.589 |
| news | 12,01 % | 3.940.537 |
| 1,93 % | 16.182.976 | |
| youtube | 0,51 % | 953.693 |
| academia | 0,40 % | 185.337 |
Yüzdeler, ilgili ref_type içinde alıntılanan URL satırlarının o kanaldaki tüm toplanan URL’lere oranını ifade eder. Sayı sütunları ham veri hacmi.
“Genel arama” search hem hacimde hem alıntı oranında baskın; nihai alıntılanan URL’lerin büyük kısmı doğrudan arama sonuç hattından gelir. Semantik arama ve SERP odağınızı, “AI’da görünmek” hedefiyle aynı çizgide tutmak mantıklı: önce o seçim havuzuna girmelisiniz.
Vertikal örnekleri (youtube kök alanı veya arXiv gibi academia kaynakları) büyük hacimle çekilse de, görünür alıntıda payları çok düşüktür.
Ayrıntı
search sınıfı, klasik web aramasıyla dönen Reddit/YouTube satırlarını da kapsar. Ayrı reddit ve youtube ref_type değerleri ise büyük olasılıkla ilave entegrasyonlardan (ör. ayrı API akışları) beslenen sonuçlara işaret eder; hacim bu yüzden yükselebilir.
İşte bu ayrım, tüm “alıntılandı mı / alıntılanmadı mı” karşılaştırmalarını yorumlarken elzem: ortalama istemde kabaca 16+ alıntılanan ve 16+ alıntılanmayan URL olsa da, alıntısız tarafta Reddit ağırlığı tabloyu ciddi çarpıtır — yani “elma ile armut”u yan yana okumamak gerekir; mümkün olduğunca ref_type bazında ayrılmak doğrudur. Bu, sorgu dili ve platform kırılımı rehberimizdeki “tek tablo cevabı yok” uyarısıyla da örtüşür.
Alıntılanmayan URL’lerin ~%67,8’i Reddit hattında
Reddit’in kendi ref_type etiketi altında, veri setinde 16M+ nokta var; buna rağmen alıntı oranı ~%1,93. Aynı zamanda alıntılanmamış URL havuzunun büyük kısmı Reddit’ten — ~67,8% — birikiyor.
Dolayısıyla model, tartışma ve “kalabalık konsensüs” için Reddit’i sıkça tüketse de, nihai yanıtta o kanala nadiren kaynak hükmünde atıf düşüyor; söyleniş: “Kitleden öğren, krediyi başkasına yaz.” Marka görünürlüğü hedefi için Reddit’i sadece “görülen link” değil, itibar ve bağlam sinyali olarak ayrıca düşünmek gerekir.
“Alıntılanmamış” tarafta çok alan: kompozisyon hatası
İlk bakışta tuhaf: alıntısız tarafta, snippet ve yayın tarihi (pub_date) gibi alanlar daha yoğun dolu görünebilir. Örneğin alıntısızlarda pub_date bir hayli yaygın (~%92) iken, alıntılananlarda daha seyrek; snippet dağılımı da farklı.
Bu, ChatGPT’nin “tarih seven” şeklinde yorumlanmamalı. Veri, alıntısız tarafta ağırlıklı olarak Reddit; Reddit API hattı pub_date gibi alanları doğal biçimde taşır — yani fark, çoğunlukla veri setinin bileşiminden kaynaklanıyor.
David McSweeney’in model üzerine analizine göre, alıntıya karar verilince snippet alanı bırakılıp tam sayfa açılması yaygındır; alıntılananlarda “düşük snippet oranı” boru hattı yapısının sonucu olabilir, alıntısız tercihinin kanıtı değil.
Araştırma etiği / metod
“Alıntılandı mı, alıntılanmadı mı” karşılaştırmaları, kaynağı tür tür (forum, arama, videolar) değil, tek torbada toplamak, veri yapay örüntülerini kanıt sanmaya yol açar. Aynı uyarı, başkaca atıf çalışmaları için de geçerlidir.
search dikeyine inildiğinde — Reddit / haber / YouTube ayrı akışlarını dışarıda bırakarak — tablo netleşir. Aynı sütun başlıkları, ekran örneğinizle de bire bir örtüşür:
| search — durum | Snippet var (yakl.) | pub_date var (yakl.) | URL sayısı |
|---|---|---|---|
| Alıntılandı | 2,52 % | 33,79 % | 22.612.529 |
| Alıntılanmadı | 0,09 % | 49,00 % | 2.951.060 |
Bu ince ayrımda snippet neredeyse hiç sinyal taşımıyor; tarih alanlarındaki fark da “kesin kazanan” söylemi için yeterince güvenilir değil. Dürüst sonuç: Snippet / tarih, bu veri setinde alıntıyı yalnız başına açıklamak için yeterince temiz ayrışmıyor.
Uygulama: “alıntı boşluğu” taraması Bir yanıtta rakibin alındığı, sizin alınmadığınız sorgu kümelerini, kendi GEO / içerik panonuzda izlemek, hangi niyetlerde geride kaldığınızı listelemek içindir. Aşağıdaki görsel, tipik alınan sayfalar türü bir panonun (kaynak çalışmada eğitim ekranı) eğilim eğrisi ve tablo bölümünü göstermek içindir — aynı mantığı kendi KPI setinize uyarlayın.
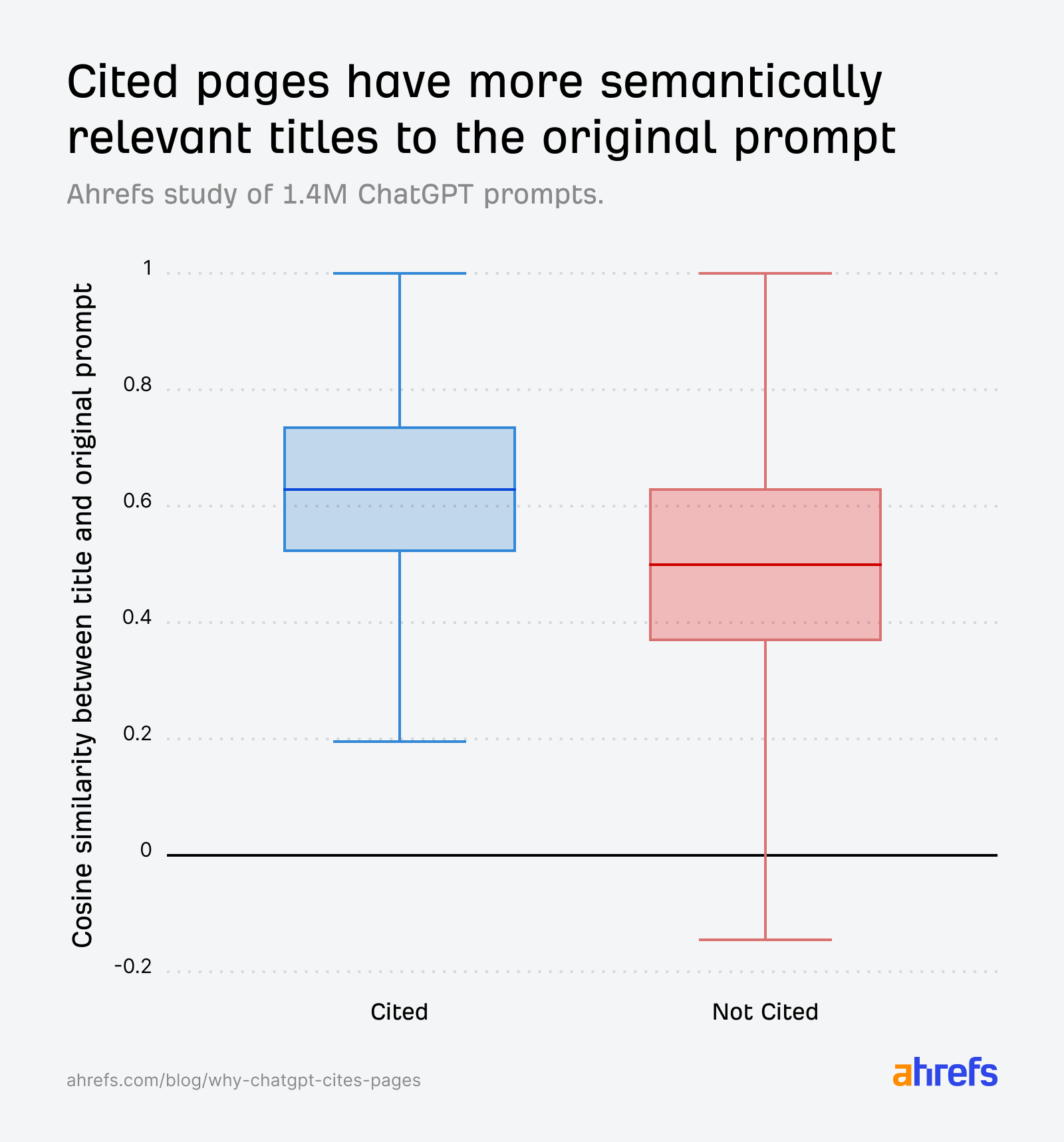
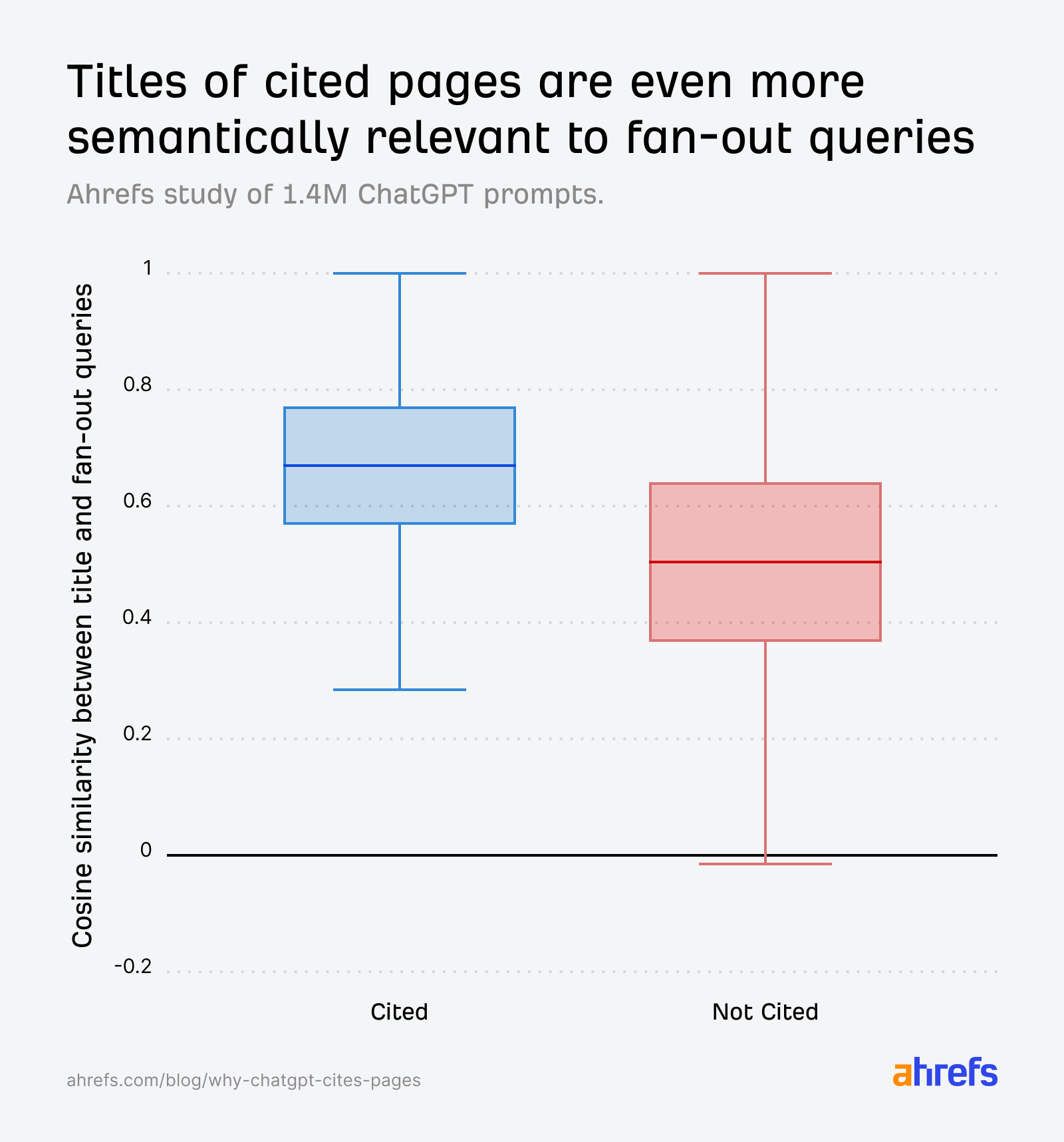
“Alıntıya uygunluk” gibi anlamsal bir puan, kapalı kutu modelde içten görünmez; dış kestirimde gömme (embedding) kosinüs benzerliği gibi açık araçlar kullanılır. ChatGPT, kullanıcının sorusundan türetilen fan-out / yayılım alt sorgularına, aday URL’leri eşler. Google Web Rehberi çizgisindeki sorgu yayılımı düşüncesi, buradaki “alt soru ağı” fikrini hatırlatır. Veri, başlık ile sorgu arasındaki yakınlığın alıntıyla ilişkili olduğunu gösterir. Yaklaşık kosinüs skorları aşağıda tabloda; üst sütun, karşılaştırılan uçlar. † Maks. eşleşme ne demek? Her fan-out için başlıkla ayrı ayrı skor alınır; tüm yorumların ortalaması yerine en iyi hizalanan alt soru dikkate alındı — sinyal zayıflaması azaltıldı.
Arama sonucu satırlarında doğal dil URL sözdizimi, daha zayıf veya anlamsız sözlüce göre yüksek alıntı payı ile ilişkilidir (ör. ~%89,8’e karşı ~%81,1 — aynı çalışma ölçeği). Özet: fan-out düzeyinde sorulan sorulara başlık ve yol, birlikte hizalanmazsa, havuzdaki o sonuç geride kalır. Okunabilir URL konusu için bkz. URL nedir, ne işe yarar rehberi. Uygulama: alt sorulara göre taslak Kendi sorgu listenizde “hangi türev alt sorunları” kapsamadığınızı kontrol listesi gibi açın; taslak bölümleriniz bu alt niyetlerle bire bir örtüşsün. Aşağıdakiler, kaynak çalışmada eğitim niteliğindeki ekran düzenlerine örnek: solda sorgu ve yanıt akışı, altta türetilmiş sorgu/fan-out satırları.
Ahrefs’in başka analizlerinde, AI asistanlarının Google organikine göre daha taze URL’lere eğilimi tartışılmıştı. Buradaki ince ayrıntı: aynı istemin kendi toplama seti içinde, nihai alıntı gören
Paradoks gibi: genel tazelik tercihi ile, set içi seçimde “daha dayanıklı” kabul edilen sayfalar. İkisi bir arada olabilir — zira Haber dikeyi
Zaman duyarlı içerik için canlı sinyal tüketimini, kaynak tarama ve hızlı yayın iş akışınızla bütünleştirirken; aşağıdaki tür ekranlar, “besleme/akış” fikrini (örnek arayüz) hatırlatır — üretim takviminize eşleştirin, ardından SEO uyumlu haber/çekirdek içerik rehberindeki kriterlerle kapatın.
Tazelik tek başına yeterli değil: fan-out ile hizasını kaçıran taze sayfa, yine toplanıp bırakılabilir. Anlam önce, tazelik (özellikle haberlerde) ikincil rekabette devreye girer. 1,4 milyon istem, çizilen tablo: ChatGPT, genel arama havuzuna yüklenir, başlık ve türetilmiş sorgu hizasını ciddi tartar, Reddit gibi toplu bağlamı sık tüketir; görünür atıf ise sınırlı kalabilir. Yalnızca “alıntısız tarafı toplu okuyorum” deyip Sonuç, içerik ve SEO tarafta: hedef, hem başlık hiyerarşisinde hem cümle düzeyinde, aracın sorduğu alt sorulara net yanıt vermek, doğru türden arama/keşif hattında görünmek ve dürüst biçimde sinyal türlerini (forum, SERP haber, alan otoritesi) ayırt etmek. Kontrol listesi (kısa)
Başlık ve
fan-out (iç alt sorgular) uyumu
Karşılaştırma
Kosinüs (yakl.)
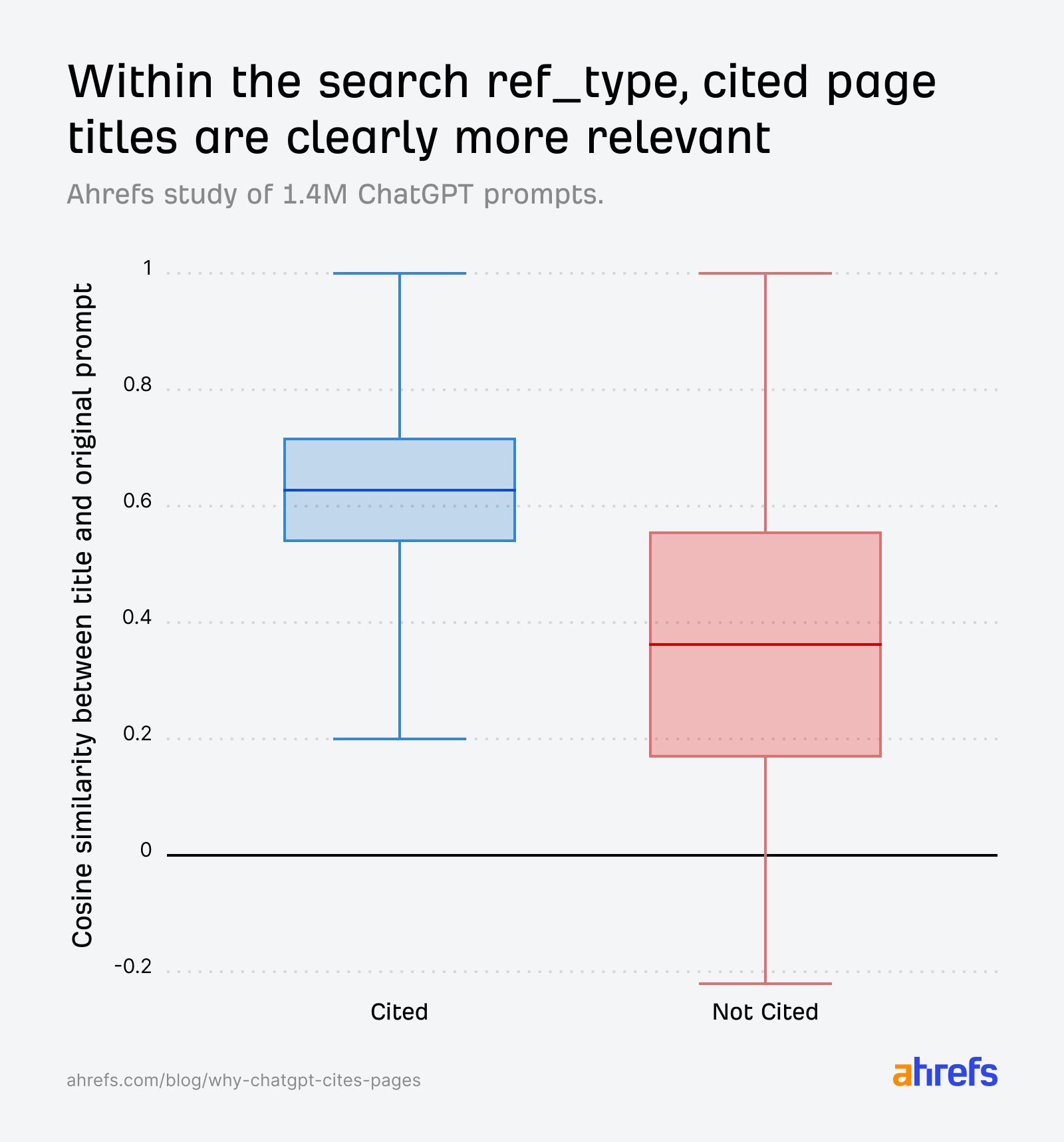
İstem ve alıntılanan sayfa başlığı
0,602
İstem ve alıntılanmamış sayfa başlığı
0,484
Fan-out sorgu ve alıntılanan başlık (maks. eşleşme†)
0,656

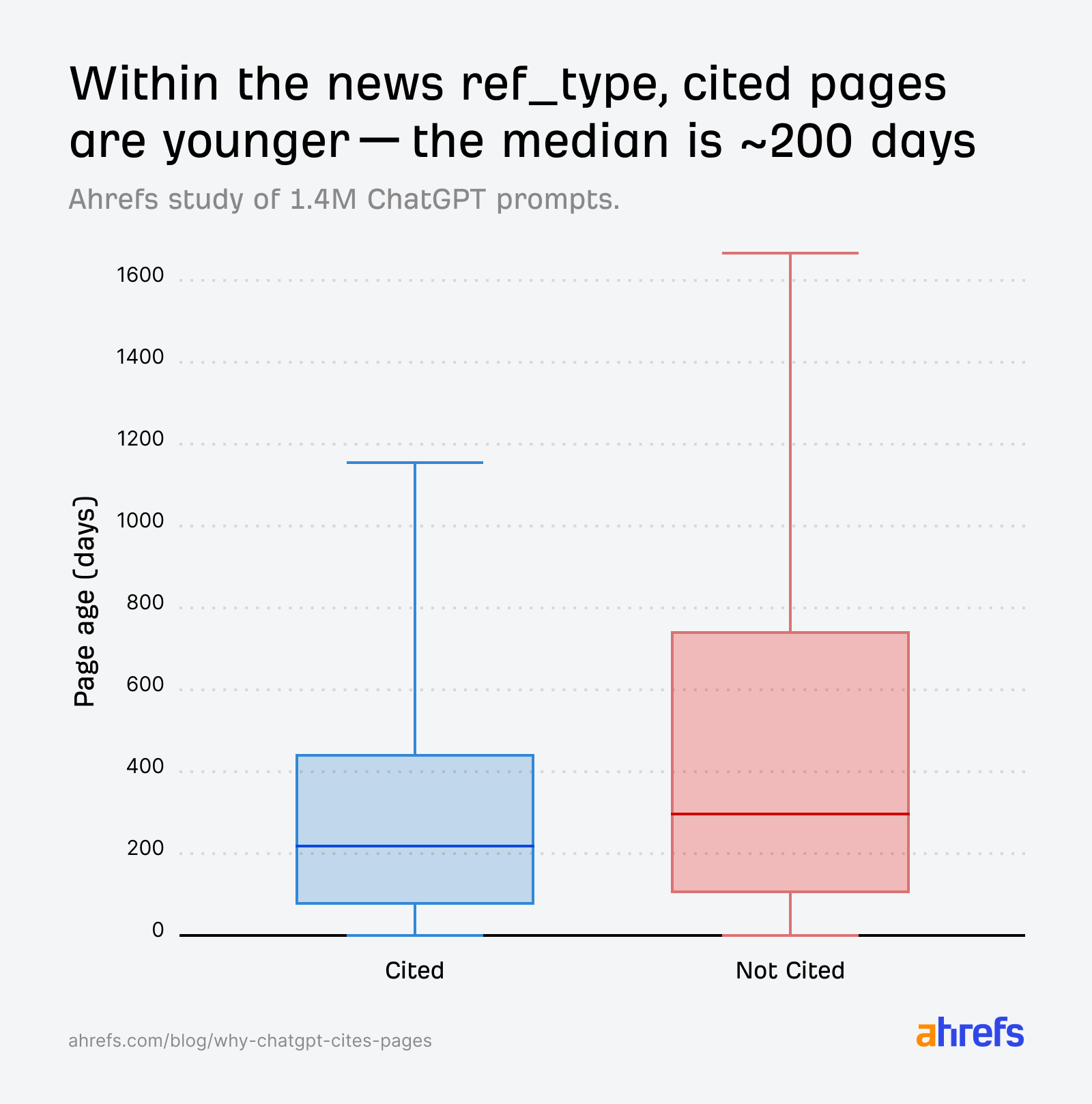
“Yaşlı” mı, “taze” mi: ikisi birden
search sayfaları, dağılım olarak nispeten “daha köklü” (medyan ~500 gün) kümeye kayarken, alıntısız tarafta tazelik ağırlığı fark edilir.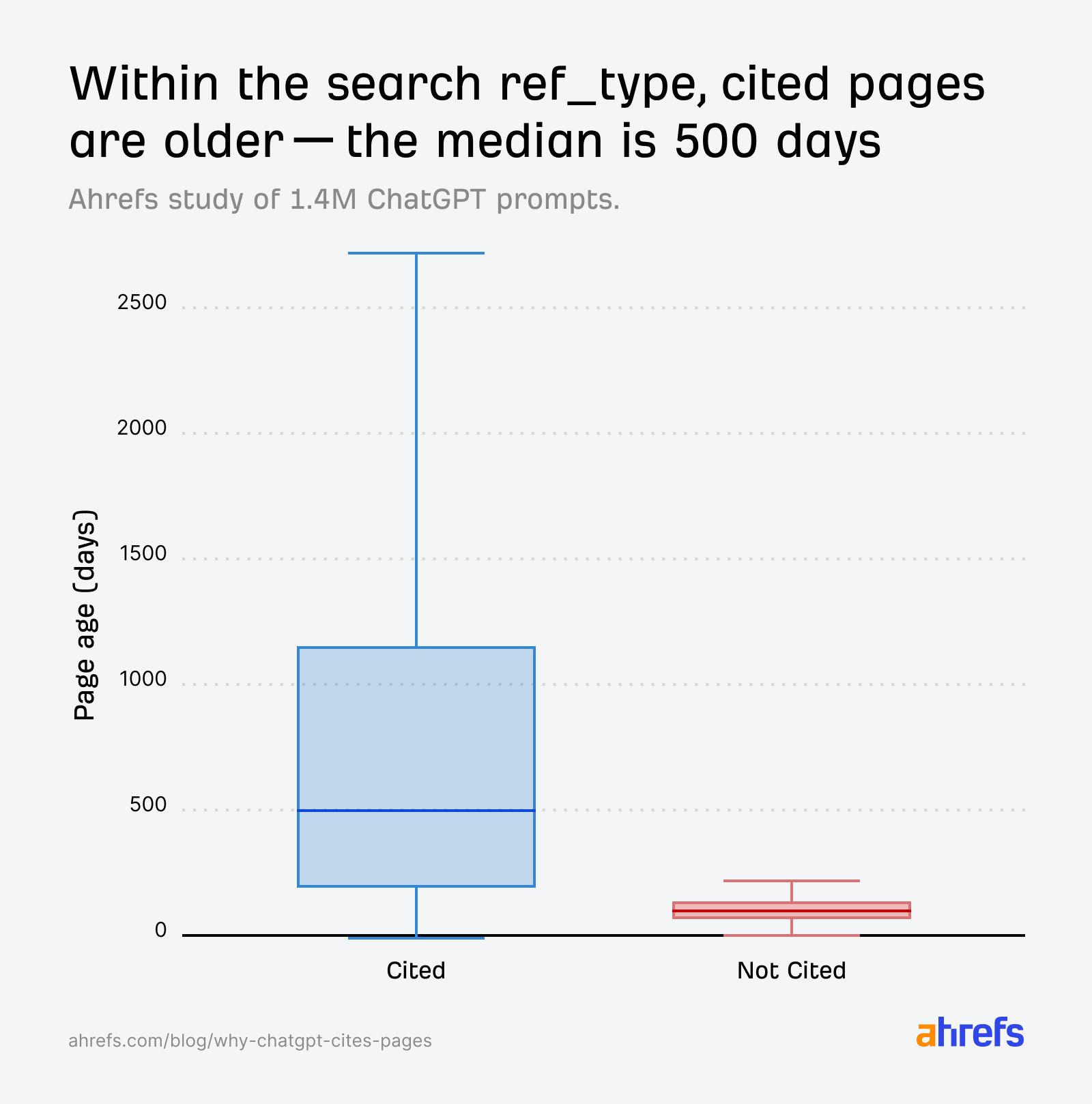
search dışı geniş popülasyonda, alıntısız taraftaki örnek hacim (URL sayısı) daha sınırlı; yaş farkı yorumunu temkinli tutmak gerekir.news ref_type’ında, başlık / istem anlamsal puanı alıntılanan ve alıntılanmamışta neredeyse aynı kalabilir; model “benzer” kalınca, zaman (sayfa yaşı) devreye ikinci eşik olarak girer. Grafik eğilimleri, alıntılanan haberlerin nispeten daha taze (ör. medyan ~200 gün) olduğuna işaret eder, alıntılanmamışlara göre (~300 gün).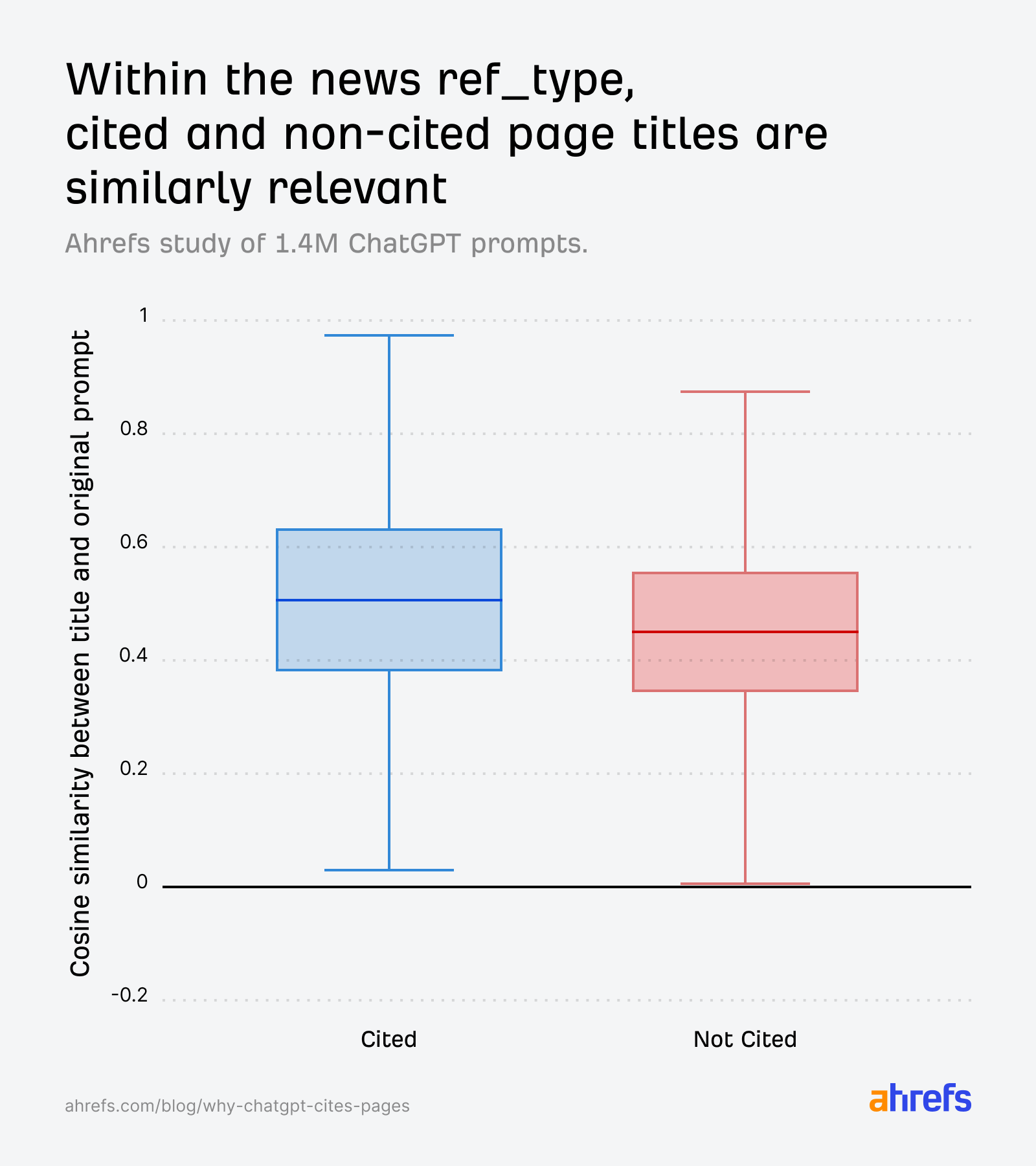
Özet: “alınabilir” (citable) ne anlama gelir?
ref_type farkını göz ardı etmeyin; sağlam analiz, kaynak türü kırılımı ister.

Oktay Çomak
Kurucu & SEO Stratejisti, SEOART
Kurumsal SEO'da veri disiplini ve ölçülebilir iş etkisine odaklanıyoruz; yol haritanızı birlikte netleştirelim.
LinkedInSEO yol haritanızı birlikte çizelim
Teknik sağlık, içerik uyumu ve görünürlük için ücretsiz ön analiz talep edin; öncelikli bulgularla sonraki adımları konuşalım.