Yapay Zeka Bilgiyi Nasıl Edinir? Eğitim Verisi, RAG, MCP ve API'ler
Yapay zekanın bilgiye nasıl ulaştığını öğrenin: eğitim verisi, RAG tabanlı grounding, MCP ve API entegrasyonları. Markanızın yapay zeka yanıtlarında yer alması için bilmeniz gereken her şey.

Eğitim verisi: Yapay zekaya bildiklerini öğreten devasa veri kümesi
Bir yapay zeka modeli tek bir soruyu yanıtlamadan önce, eğitim adı verilen uzun ve son derece maliyetli bir süreçten geçer. Bu süreçte model; kamuya açık web taramaları, kitaplar, ansiklopedi makaleleri, kod depoları ve lisanslı veritabanları gibi kaynaklardan derlenen milyarlarca metin, görsel ve kod örneğini sindirerek tüm bu veriler üzerindeki kalıpları tahmin etmeyi öğrenir. Eğitim tamamlandığında model, o tarihe kadar üretilmiş insan bilgisinin istatistiksel bir anlık görüntüsünü adeta ezberleyen bir yapıya kavuşur.
Yapay zekanın dünyayı "anlaması" tam da bu şekilde gelişir. Eğitim verisinde farklı varlıkların ne sıklıkla geçtiği ve bu varlıkların hangi kelimelerle birlikte kullanıldığı, modelin o varlığa ilişkin zihinsel haritasını şekillendirir. Örneğin bir markanın adı, çevre dostu üretim veya yüksek kalite gibi kavramlarla sürekli birlikte geçiyorsa model de o markayı bu niteliklerle ilişkilendirir. Dil modelleri, markanız ile belirli kavramlar arasındaki ilişkileri öğrenir; bu anlamsal bağlantılar modelin sizi nasıl tanımladığını ve önerdiğini doğrudan etkiler.
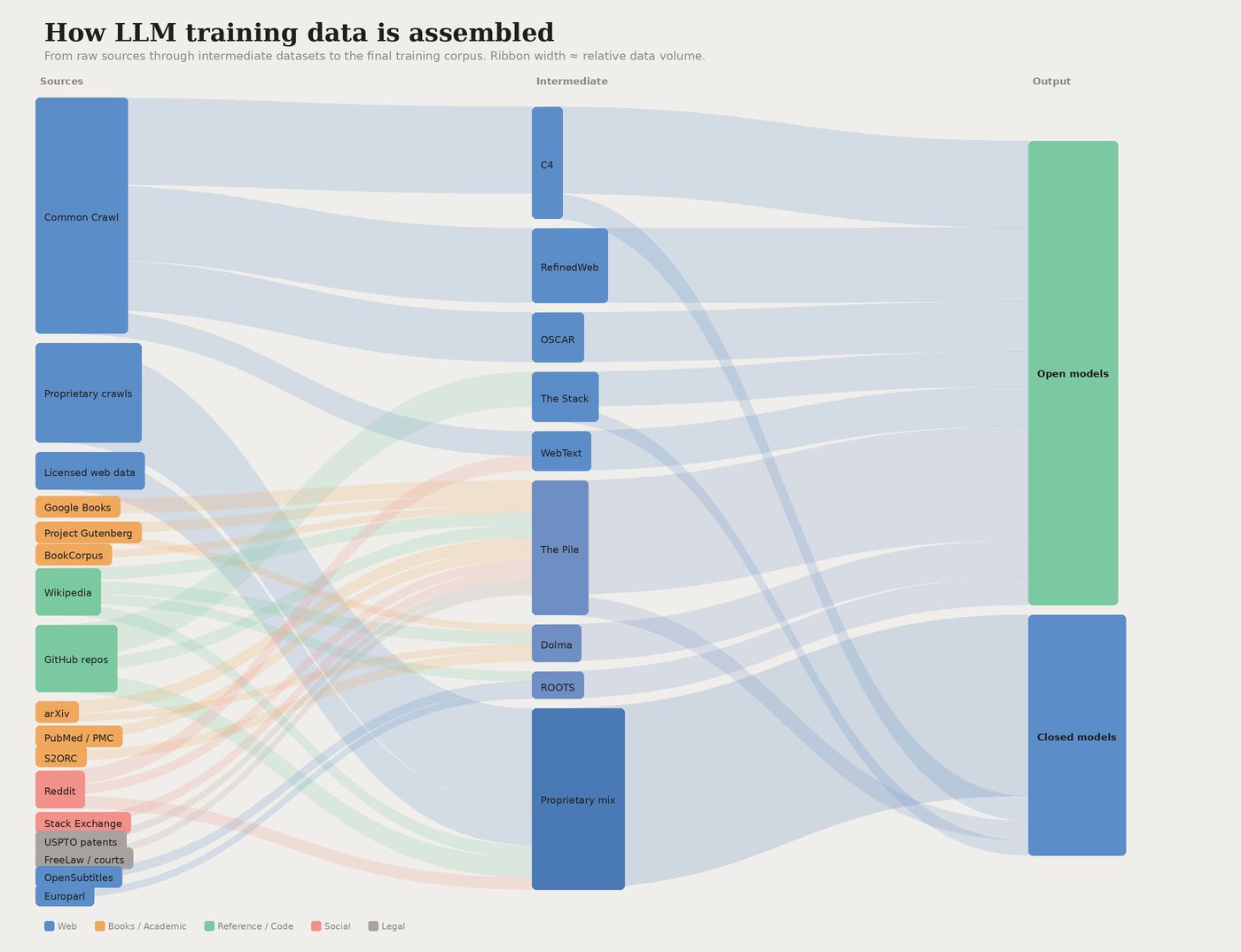
Eğitim sürecindeki ölçek, kavraması güç bir boyuta ulaşmıştır. Büyük modeller için eğitim verisi trilyonlarca token ile ölçülür; bu da inanılmaz maliyetler anlamına gelir. GPT-4'ün eğitim maliyetinin yaklaşık 78 milyon dolar, Google'ın Gemini Ultra modelinin ise yaklaşık 191 milyon dolar olduğu tahmin edilmektedir. Küresel yapay zeka eğitim veri seti pazarının 2025 yılında 3,2 milyar dolara ulaştığı ve yüzde 22,6'lık yıllık büyüme oranıyla 2033'te 16,3 milyar dolara çıkması beklenmektedir; bu rakamlar verinin tüm sektör için ne denli merkezi bir konuma geldiğini açıkça ortaya koymaktadır.
Anlaşılması gereken kritik nokta şudur: eğitim sona erdiğinde modelin bilgisi dondurulur. Model yeni olaylardan öğrenemez; dün, geçen ay ya da eğitim verilerinin kesildiği tarihten sonra yaşananlar hakkında hiçbir fikri yoktur. Bazı sağlayıcılar modellerini periyodik olarak daha yeni verilerle ince ayar yaparak günceller; ancak bu da sürekli haber okuyan bir yapıdan değil, ayrı bir yazılım güncellemesi sürecinden ibarettir.
Eğitim verisinin bir diğer önemli zaafiyeti ise halüsinasyondur. Model güvenilir eğitim verisine sahip olmadığı durumlarda boşluğu makul görünen bir şeyle doldurur: uydurulmuş bir kaynak, asılsız bir istatistik, özgüvenli ama yanlış bir yanıt. Modelin makalenin şaka amaçlı yazıldığını bilmesi için hiçbir yolu yoktur; içerik yeterince yetkili görünüyorsa kalıba uyar ve güvenle sunar.
Grounding: RAG yapay zekaya nasıl güncel bilgi erişimi sağlar?
Retrieval-Augmented Generation, yani kısaca RAG, bilgi kesim tarihi sorununu aşmak için kullanılan temel tekniktir. Model, yalnızca eğitim sırasında öğrendiklerine güvenmek yerine, bir soru sorulduğu anda ilgili belgeleri çekip bu belgeleri yanıt üretirken bağlam olarak kullanır.
Bunu kapalı kitap sınavı ile açık kitap sınavı arasındaki fark olarak düşünebilirsiniz. Yalnızca eğitime dayanan model her şeyi bellekten yanıtlamak zorundadır. RAG özellikli model ise önce arama yapabilir, sonra yanıtlar. Sonuç daha güncel ve prensipte daha doğrulanabilir olur; çünkü yanıt istatistiksel örüntü eşleştirmesi yerine gerçekten alınan içeriğe dayandırılmıştır.
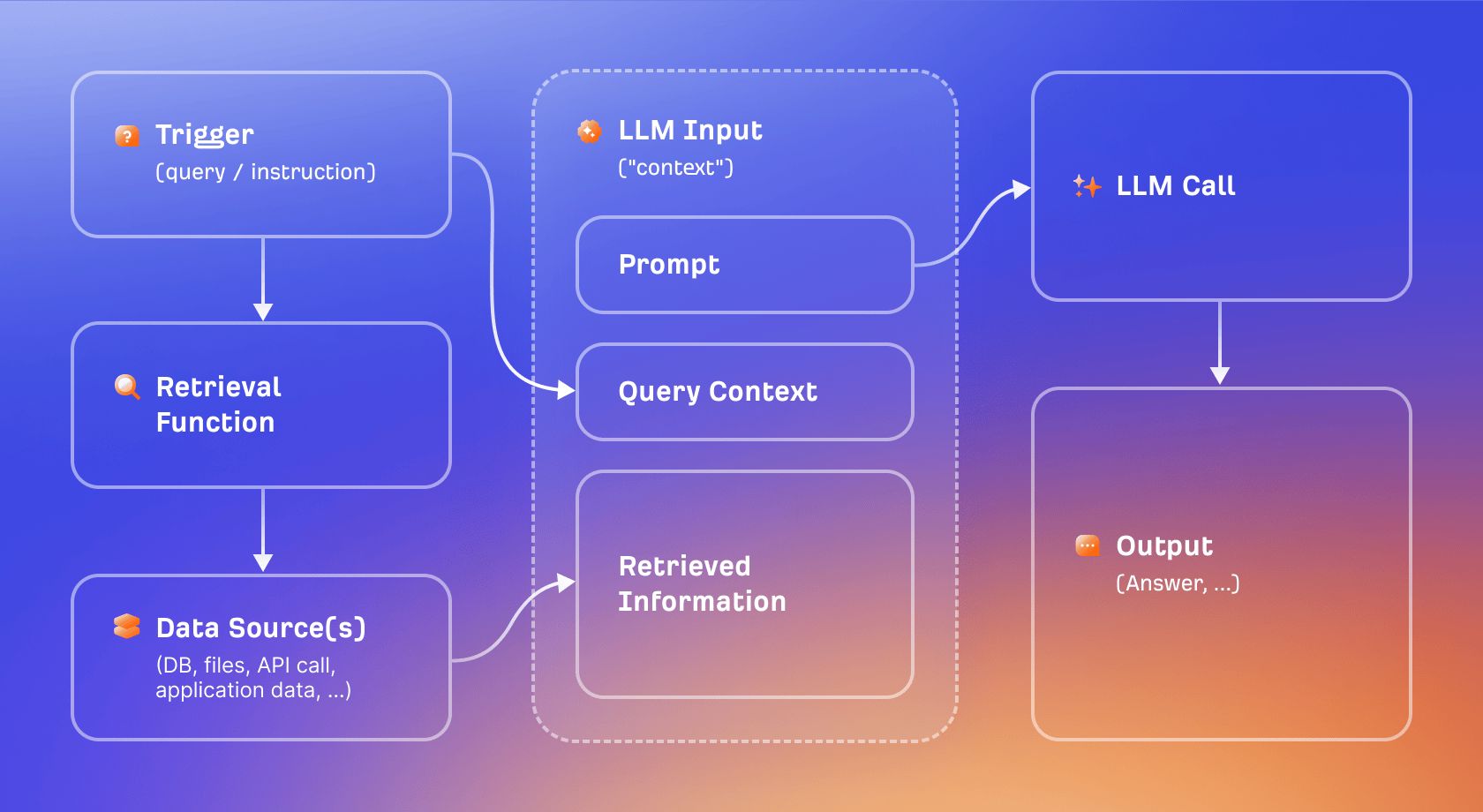
Grounding bu çapalama işleminin daha geniş kapsamlı adıdır. Bir yapay zeka yanıtı groundlandığında, belirli alınan kaynaklara bağlanır ve bu durum halüsinasyon riskini önemli ölçüde azaltır. Grounding terimi, istatistikten ve başlangıçta kartografyadan gelmektedir; haritanın gerçeklikle örtüştüğünü doğrulamak için dışarı çıkmak anlamına gelir. Yapay zeka söz konusu olduğunda da mantık aynıdır: modelin ürettiği yanıtın gerçek kaynaklara dayandığını teyit etmek.
ChatGPT ve Gemini gibi yapay zeka arama motorları bu grounding süreci için Google ve Bing gibi geleneksel arama dizinlerini kullanır. Dolayısıyla geleneksel aramada iyi bir SEO performansı sergilemek, yapay zeka görünürlüğünüzü de doğrudan artırır. Yapay zekanın aradığı terimde arama dizininde ne kadar üst sıralarda yer alırsanız, alındığınızda ve yanıtta kaynak olarak gösterilme olasılığınız o kadar yüksek olur.
Her yapay zeka ürünü RAG kullanmaz. Tarama özelliği devre dışı bırakılmış temel bir sohbet asistanı oturumu örneğin tamamen eğitime dayalıdır: güncel bilgiye erişimi yoktur ve yanıtlarını canlı kaynaklara karşı doğrulayamaz. Bu yaklaşımın avantajı hız ve basitliktir. Yalnızca eğitime dayalı yanıtlar hızlıdır; ancak kalıcı olarak eskimiş durumdadırlar. RAG gecikme süresi ekler ve yeni bir başarısızlık modu getirir (alma hataları: yanlış kaynak veya düşük kaliteli kaynak çekme), ama güncelliği mümkün kılar.
MCP'ler ve API'ler: Yapay zeka ajanları modelin gerçek zamanlı erişimini nasıl genişletir?
RAG, güncel bilgiyi yapay zeka yanıtlarına dahil etmenin bir yoludur. Ancak modern yapay zeka sistemleri giderek daha ileri gitmekte; modellere sohbet ortasında harici araçları çağırma yeteneği kazandırmaktadır. Bu, yapay zeka ajanları alanına girmektedir.
Bir yapay zeka ajanı yalnızca belge almakla kalmaz; bir görevi yerine getirirken API'leri sorgulayabilir, aramalar yapabilir, kod çalıştırabilir ve canlı veri kaynaklarıyla etkileşime girebilir. Üretken yapay zeka ile ajantik yapay zeka arasındaki temel fark tam da burada yatmaktadır: biri statik örüntülere dayanırken diğeri dinamik olarak araç çağırır ve süreci adım adım ilerletir.

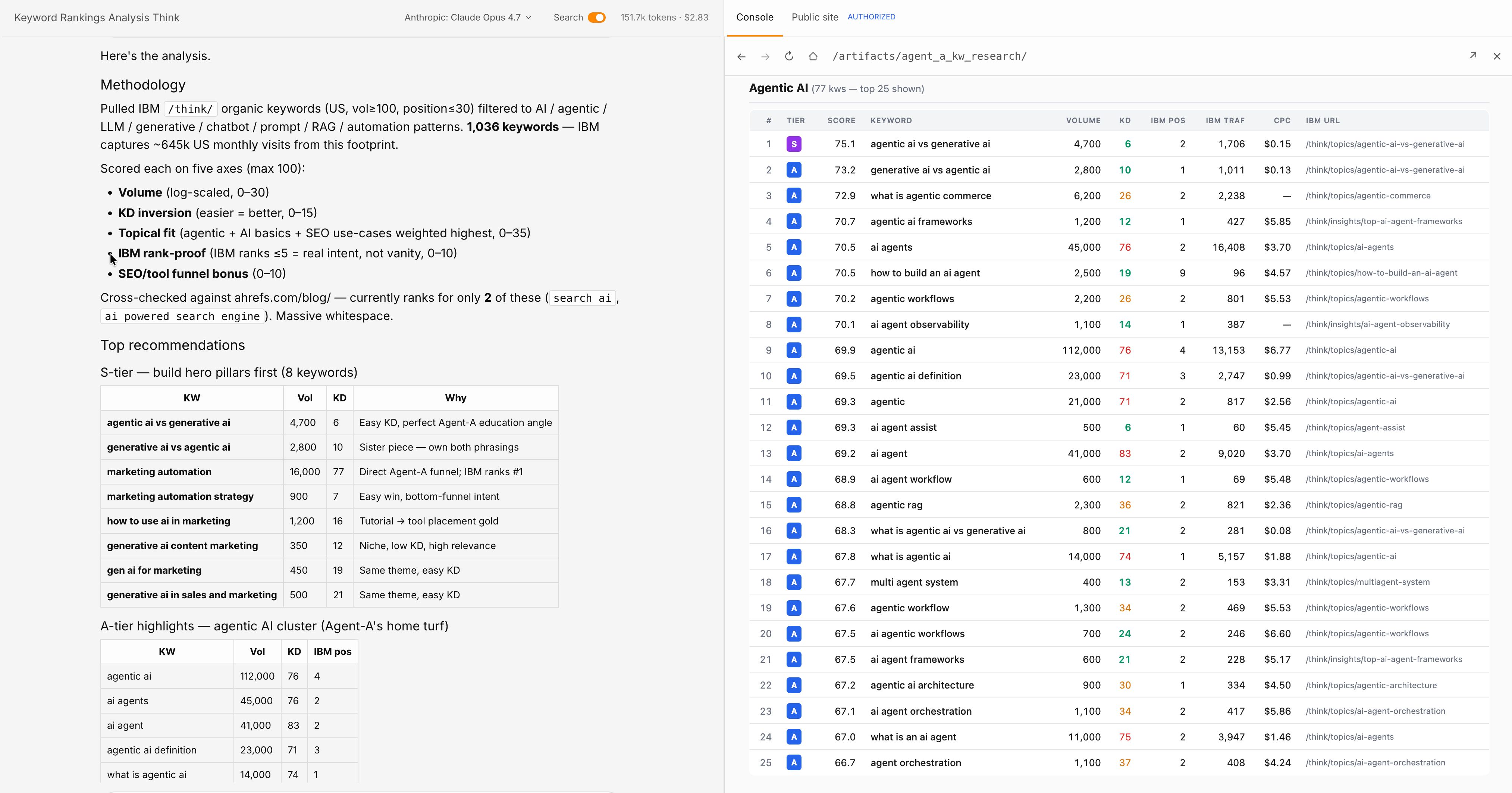
Bu altyapı için gelişmekte olan standart Model Context Protocol (MCP) olarak adlandırılmaktadır. MCP, yapay zeka modellerinin harici veri kaynaklarına yapılandırılmış bir şekilde bağlanmasını sağlayan bir standarttır. Örneğin bir SEO aracının MCP entegrasyonu, yapay zeka ajanlarının anahtar kelime metrikleri, geri bağlantı verileri veya rekabetçi içgörüler gibi verileri bir görev sırasında doğrudan sorgulamasına olanak tanır; kullanıcının iş akışından çıkmasına gerek kalmaz.
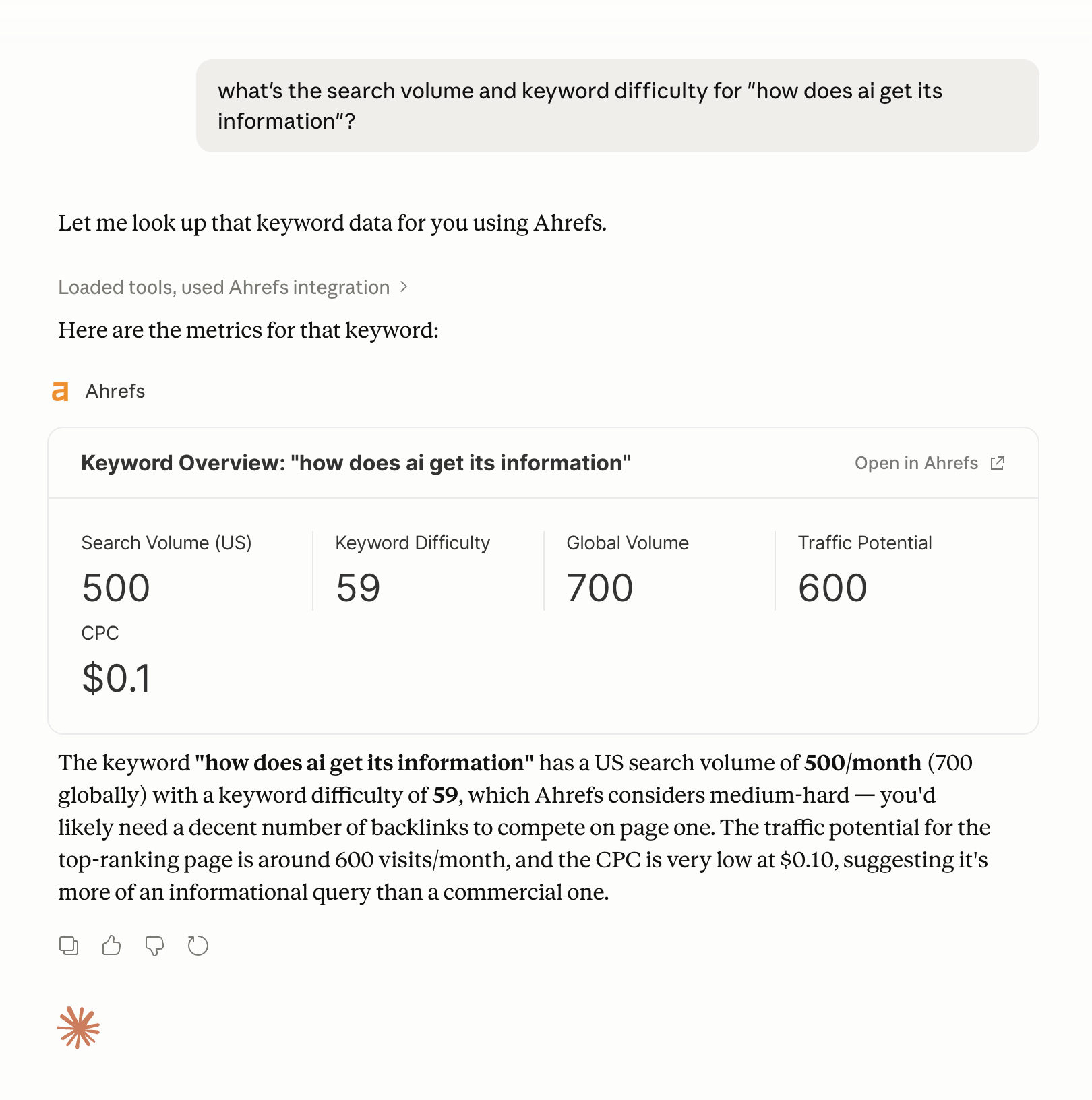
Araç ile zenginleştirilmiş yapay zekanın yalnızca çağırdığı araçlar kadar güvenilir olduğunu unutmamak gerekir. API hatalı veri döndürürse yapay zeka özgüvenle hatalı bir yanıt üretir. Modelin zekası sizi çöp girdilerden korumaz. Ancak araç entegrasyonları, modelin erişimini herhangi bir eğitim veri setinin kapsayabileceğinin çok ötesine taşır ve bu, özellikle pazarlama ile SEO görevleri için büyük bir fark yaratır.
Yapay zekanın sizi bulmasını ve güvenmesini isteyen markalar için ne anlam ifade ediyor?
Yapay zekanın bilgiyi nereden aldığını anladığınızda, markanızın atıfta bulunulma şansını en üst düzeye çıkarmak için nerede yer almanız gerektiğini de anlarsınız. Bu üç katmanın her biri, markanızın yapay zeka yanıtlarında görünür olup olmayacağını etkiler.
Site dışı atıflar: Yapay zekanın markanızı doğru şekilde temsil etmesini istiyorsanız başlangıç noktası kendi web siteniz değil, site dışı atıflardır. Modeller markalar hakkında eğitim aldıkları kaynaklardan öğrenir: basın haberleri, üçüncü taraf incelemeler, forum tartışmaları, ansiklopedi girişleri ve yetkili yayınlardaki alıntılar. Yalnızca kendi alan adında var olan bir marka, modelin eğitim verisine büyük ölçüde görünmezdir.
Sorgu yayılımı: Marka tanınırlığının ötesinde, sorgu yayılımını da düşünmeniz gerekir; yani yapay zeka sistemlerinin bir temel konu etrafında oluşturduğu ilişkili soruları. Belirli bir yazılım kategorisi için sıralanan bir markanın aynı zamanda sprint değerlendirmesinin nasıl yapılacağı veya iki metodolojinin karşılaştırması gibi içerikleri de hedeflemesi gerekir; çünkü kullanıcı ilk sorguyu takip ettiğinde yapay zekanın ortaya çıkaracağı sorular bunlardır. Temel konularınızın etrafındaki tam anlamsal komşuluğu kapsayan içerikler oluşturmak, o genişlemede görünme şansınızı artırır.
Teknik erişilebilirlik: Temiz HTML yapısı, hızlı yükleme süreleri ve doğru yapılandırılmış bir robots.txt dosyası, yapay zeka tarayıcılarının içeriğinizi okuyup okuyamayacağını etkiler. llms.txt, dil modellerinin sitenizin yapısını anlamasına yardımcı olmak için önerilmiş bir standarttır; ancak 2026 itibarıyla hiçbir büyük dil modeli sağlayıcısı buna saygı duyduklarını resmi olarak doğrulamamıştır.
Yapay zeka görünürlüğünü ölçmek için marka izleme araçları kullanmak giderek daha önemli hale gelmektedir. ChatGPT, Gemini, Perplexity, yapay zeka genel bakışları ve diğer platformlarda markanızın yapay zeka tarafından üretilen yanıtlarda rakiplerinize kıyasla ne sıklıkla anıldığını takip etmek, stratejinizi veriye dayalı biçimde şekillendirmenizi sağlar.
| Bilgi Katmanı | Ne Sağlar | Güncellik | Başlıca Başarısızlık Modu |
|---|---|---|---|
| Eğitim Verisi | Temel dünya bilgisi ve dil anlayışı | Dondurulmuş (güncelleme yok) | Halüsinasyon, eskimiş bilgi |
| RAG / Grounding | Canlı belgelerden alınan güncel bağlam | Yüksek (gerçek zamanlıya yakın) | Alma hatası, yanlış kaynak |
| MCP / API Araçları | Canlı veritabanları ve harici sistemler | Gerçek zamanlı | Hatalı API verisi, araç arızası |
Tablo: Üç bilgi katmanının karşılaştırmalı özeti — her katmanın gücü ve zayıf noktaları.
Sonuç: Üç katmanı bir arada değerlendirmek
Yapay zeka bilgisi üç katmandan gelir: dondurulmuş eğitim verisi, alınan canlı belgeler ve API'ler ile MCP'ler gibi bağlı harici araçlar. Her katmanın farklı bir doğruluk profili, güncellikle farklı bir ilişkisi ve farklı bir başarısızlık şekli vardır.
Eğitim verisi temeli oluşturur; kapsamlı, pahalı ve statiktir. RAG ve grounding, alma güvenilirliği pahasına güncellik katar. MCP ve API aracılığıyla gerçekleştirilen araç entegrasyonları ise bunu daha da ileri taşır; yapay zekaya ihtiyaç duyulan anda canlı ve yetkili verilere erişim sağlar.
Markanızın yapay zeka tarafından doğru şekilde temsil edilmesini istiyorsanız, bu üç katmanın nasıl çalıştığını anlamak stratejinizin temelini oluşturmalıdır. Hangi katmanın soruyu yanıtladığını bilmek; bir yanıta ne kadar güvenmeniz gerektiğini, nerede içerik boşluğu olduğunu ve markanızın görünürlük çalışmalarını nereye yönlendirmeniz gerektiğini anlamamızı sağlar. Yapay zeka arama motoru görünürlüğü artık geleneksel SEO ile iç içe geçmiş bir disiplin haline gelmiştir ve her iki alanı birlikte ele almak rekabet avantajı sağlar.

Oktay Çomak
Kurucu & SEO Stratejisti, SEOART
Kurumsal SEO'da veri disiplini ve ölçülebilir iş etkisine odaklanıyoruz; yol haritanızı birlikte netleştirelim.
LinkedInSEO yol haritanızı birlikte çizelim
Teknik sağlık, içerik uyumu ve görünürlük için ücretsiz ön analiz talep edin; öncelikli bulgularla sonraki adımları konuşalım.