İçerik Mühendisliği Nedir ve Nasıl Yapılır?
İçerik mühendisliği; araştırmadan yayına kadar tüm editöryal süreci otomatikleştiren yapay zeka destekli pipeline sistemleri tasarlamak demektir. Bu kapsamlı rehberde içerik mühendisliğinin tanımını, iki farklı türünü, temel bileşenlerini ve altı adımlı uygulama yöntemini bulabilirsiniz.

İçerik mühendisliği nedir?
Bir içerik yazarı blog yazısı üretir. Bir içerik stratejisti hangi konuların ele alınacağına karar verir. Bir içerik mühendisi ise içeriği üreten ve insanlar ile yapay zeka tarafından keşfedilebilir kılan sistemleri tasarlar. Başka bir deyişle içerik mühendisliği, içeriği parça parça üretmek yerine içeriği ortaya çıkaran mekanizmaları kurmak anlamına gelir.
Bu sistemler, eskiden bir yazarın omuzladığı işlerin tamamını devralır: konu araştırması, taslak oluşturma ve düzenleme, arama motorları ile yapay zeka yüzeyleri için optimizasyon, içerik yönetim sistemine (CMS) yayınlama ve performans ölçümü. İçerik mühendisi, tüm bu adımları yapay zeka aracılığıyla birbirine bağlayan pipeline'ı tasarlar; böylece ekip marka tutarlılığını ve kaliteyi kaybetmeden daha fazla içeriği daha hızlı yayınlayabilir.
İçerik mühendisliği kavramı, editoryal kararların tek seferliğe indirilmesi ilkesine dayanır. Kıdemli bir yazarın her içerik parçası için verdiği ses tonu, yapı ve kaynak gösterme kararları bir kez sistem içinde kodlanır; bundan sonra pipeline her çalıştığında aynı kararlar otomatik olarak uygulanır. Bu yaklaşım hem üretim kapasitesini artırır hem de ekibin enerjisini asıl değer yaratan yaratıcı düşünceye yönlendirmesini sağlar.

İki tür içerik mühendisi vardır
"İçerik mühendisi" terimi pratikte iki farklı bağlamda kullanılır ve bu iki profil hem sorumluluk hem de çalışma biçimi açısından birbirinden belirgin şekilde ayrışır.
Yapılandırılmış içerik mühendisi: Bu profil, büyük organizasyonların birden fazla kanal, ürün ve dil genelinde tutarlı içerik yayınlayabilmesi için taksonomi ve meta veri şemaları tasarlar. Büyük teknoloji şirketlerinin destek dokümanları veya uluslararası perakende markalarının ürün bilgi sistemleri bu yaklaşımın somut örnekleridir. Temel hedef, içeriğin yapısını ve sınıflandırmasını standartlaştırmaktır.
Yapay zeka pipeline içerik mühendisi: Bu profil ise içeriğin arama motoru tarayıcıları, yapay zeka botları, ajanlar ve henüz gelişmekte olan keşif mekanizmaları tarafından bulunabilmesi için içerik oluşturma ve optimizasyon süreçlerini otomatikleştirir. Odak noktası, ham bir anahtar kelimeden yayına hazır bir içerik parçasına ulaşana kadar geçen tüm adımları sistematik hale getirmektir.
Pratik uygulamalarda ve iş ilanlarında giderek daha fazla karşılaşılan ikinci tip, yani yapay zeka pipeline içerik mühendisliği modeli, içerik ekiplerinin ölçeklenme sorununa yanıt olarak ortaya çıkmıştır. Mevcut içerik üretim tavanını kaldırmak, yayın hızını artırmak ve insan editörlerin zamanını stratejik kararlara ayırmak için bu modelin benimsenmesi giderek yaygınlaşmaktadır.
İçerik mühendisliği nasıl çalışır?
İçerik mühendisliğini tanımlayan dört örtüşen uygulama alanı vardır ve çoğu mühendis bunların hepsini eş zamanlı olarak yürütür. Bu dört alan; pipeline tasarımı, beceri ve prompt mühendisliği, bilgi ve gerçek kaynak yönetimi ile orkestrasyon ve yönetişimdir.

Bu dört alanın birbirini tamamlayan bir döngü oluşturduğunu anlamak kritik önemdedir. Pipeline tasarımı olmadan beceriler nerede çalışacağını bilemez; bilgi tabanı olmadan pipeline çıktısı jenerik kalır; orkestrasyon ve yönetişim olmadan ise tüm sistem insan müdahalesi olmaksızın çalışamaz.
Pipeline tasarımı
Pipeline tasarımı, editoryal süreci ayrık ve otomatikleştirilebilir adımlara bölmek anlamına gelir. Örneğin bir içerik dağıtım pipeline'ı, yayınlanmış bir makaleyi beş aşamadan geçirebilir: temel noktaları çıkarma, formata özgü varyantlar oluşturma, her varyantı belirli bir platforma uyarlama, yayın zamanlarını zamanlama ve performans verilerini bir panoya geri kaydetme.
İyi tasarlanmış bir pipeline'ın ayırt edici özelliği, her adımın bir öncekinin çıktısını girdi olarak almasıdır. Bu zincirleme yapı sayesinde sistem kendi kendini besler; bir aşamada yapılan iyileştirme otomatik olarak sonraki aşamalara yansır. Örneğin araştırma aşamasında elde edilen yüksek kaliteli anahtar kelime verisi, taslak aşamasında daha odaklı ve alaka düzeyi yüksek bir içerik üretilmesini doğrudan etkiler.
Pipeline tasarımında yapılan yaygın bir hata, adımları çok geniş tanımlamaktır. "Araştır ve yaz" gibi tek bir adım, sistemin ne yapacağını belirsiz kılar. Bunun yerine "Anahtar kelime hacmini çek", "İlk 10 SERP sonucunu analiz et", "Sık sorulan soruları listele" gibi granüler adımlara bölmek, hem kaliteyi artırır hem de hata ayıklamayı kolaylaştırır.
Beceri ve prompt mühendisliği
Prompt'lar, tek bir görev için bir modele verilen tek seferlik talimatlardır. Beceriler (skills) ise tekrar eden bir görev ortaya çıktığında modelin başvurabileceği, yeniden kullanılabilir ve paketlenmiş talimatlardır; çoğunlukla örnekler veya referans dosyalarıyla birlikte gelirler. Beceriler ve prompt'lar, pipeline'ın her aşamada ne yapacağını bilmesini sağlar.
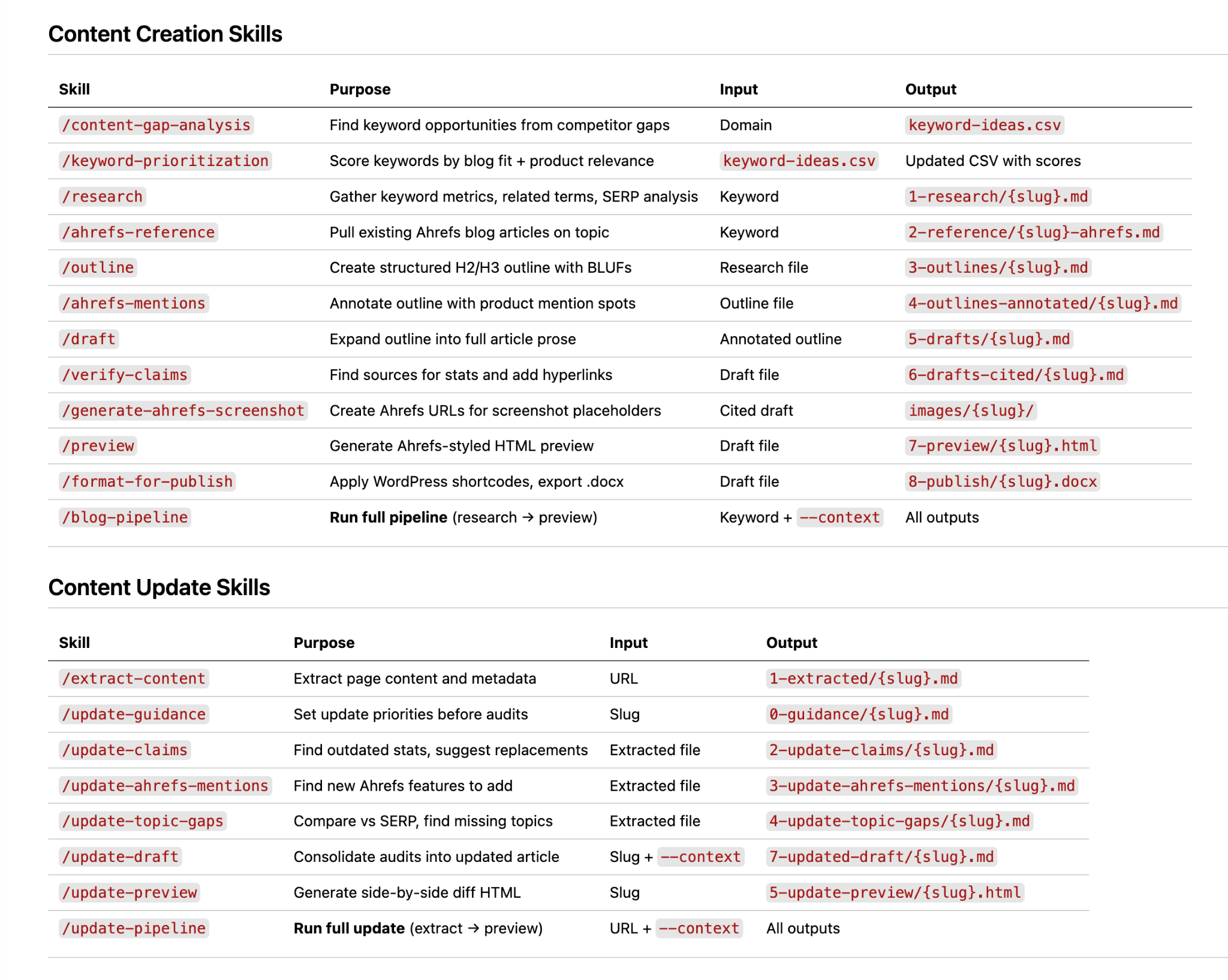
Bir taslak becerisi, iyi bir makalenin nasıl başlayıp biteceğini kodlar. Bir alıntı becerisi, ekibin kaynak standartlarını kapsar. Bir biçimlendirme becerisi, CMS'nin beklediği kısa kodları tanımlar. Bu becerilerle birlikte, kıdemli bir yazarın her içerik parçası için aldığı editoryal kararlar bir kez yazılır ve pipeline her çalıştığında tüm ekip tarafından otomatik olarak kullanılır.
Beceri dosyaları genellikle düz metin veya Markdown formatında yazılır. SKILL.md gibi standart bir dosya adlandırma kuralı benimsemek, büyüyen bir beceri kütüphanesinde düzeni korumayı kolaylaştırır. Her beceri dosyasına görevin amacını, bağlamı, adım adım talimatları ve çıktı formatını dahil etmek, modelin tutarlı sonuçlar üretmesini güvence altına alır.
Bilgi ve gerçek kaynak yönetimi
Pipeline'lar, kendilerini besleyen doğru bilgi olmadan işe yaramaz hale gelir. Bilgi yönetimi ve gerçek kaynak (Source of Truth — SoT) sistemi, her şeyin üzerine inşa edildiği gösterişsiz bir temeldir: marka yönergelerinin, ürün detaylarının, tescilli araştırmaların ve konu uzmanı röportajlarının yapılandırılmış ve birbirine bağlı olduğundan emin olmak.
Bu yapı kurulmadığında yapay zeka boşlukları jenerik dil ve bilgilerle doldurur. Sonuç olarak ortaya çıkan içerik, şirketin kendine özgü perspektifini, veri derinliğini ve marka sesini yansıtmaktan uzak kalır. Rakiplerden farklılaşan içerik üretmenin önündeki en büyük engellerden biri budur.
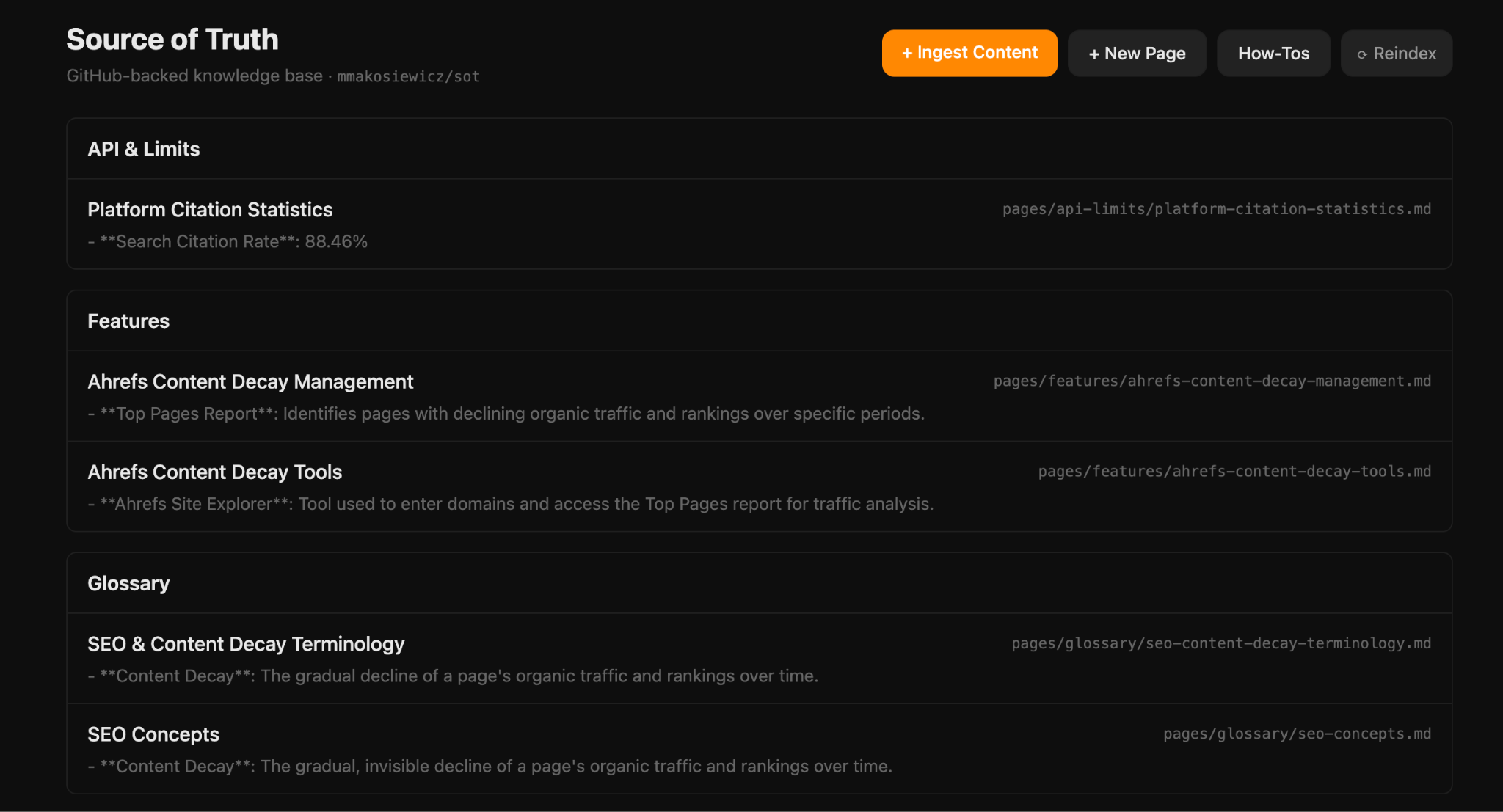
Etkili bir bilgi tabanı oluştururken marka ses rehberi, ideal müşteri profili (ICP), ürün konumlandırma dokümanları, tescilli araştırma raporları, müşteri görüşme transkriptleri ve sektöre özgü terminoloji sözlükleri temel bileşenler olarak öne çıkar. Bu materyallerin düz dosya halinde tutulması yeterli değildir; birbirleriyle bağlantılı, versiyonlanmış ve pipeline tarafından sorgulanabilir şekilde yapılandırılması gerekir. Retrieval-Augmented Generation (RAG) yaklaşımı, modelin bu bilgi tabanından gerçek zamanlı olarak beslenmesini mümkün kılar.
Orkestrasyon ve yönetişim
Orkestrasyon; pipeline'ı manuel olarak başlatmaktan kurtaran, onu kendi kendine çalışan bir sisteme dönüştüren zamanlama ve tetikleme mekanizmasıdır. Günlük yenileme işleri, haftalık raporlar, olay tetiklemeli iş akışları bunların örnekleridir. İyi kurulmuş bir orkestrasyon katmanı sayesinde içerik mühendisi, tekrar eden görevleri tetiklemek yerine sistem mimarisini geliştirmeye odaklanabilir.
Yönetişim ise sistemin kalitesiz iş çıkarmasını önleyen kurallardır: gerçek kontrolü, kaynak doğrulama, marka sesi denetimi ve insan inceleme kontrol noktaları. Yönetişim olmadan otomasyon, hataları ölçeklendirir. Yanlış bir istatistiğin veya doğrulanmamış bir iddianın tek bir makalede yayınlanması ile yüzlerce makalede yayınlanması arasındaki fark, tam da bu yönetişim katmanının varlığı veya yokluğundan kaynaklanır.
Pratik bir yönetişim çerçevesi şunları içerebilir: her çıktı aşamasında otomatik gerçek kontrolü, doğrulanamayan iddiaların [UNVERIFIED] etiketiyle işaretlenmesi, marka sesi puanlaması, belirli hassasiyet eşiklerini aşan içerikler için zorunlu insan incelemesi ve yayın öncesi biçimlendirme denetimi. Bu kontroller ne kadar sistematik kurulursa insan editörlerin manuel denetim yükü o kadar azalır.
İçerik mühendisinin günlük sorumlulukları nelerdir?
Bir içerik mühendisi, içerik ekibinin içerik üretmek, optimize etmek ve dağıtmak için kullandığı yapay zeka destekli sistemleri kurmaktan ve sürdürmekten sorumludur. 2025–2026 yıllarında yayınlanan ABD'li iş ilanlarının analizi, bu rolün içeriği en iyi tanımlayan sorumluluğun yapay zeka destekli içerik pipeline'ı oluşturmak olduğunu ortaya koymuştur; bu oran yüzde seksen beşe ulaşmakta ve yazmayı bile geride bırakmaktadır. Bunu yüzde yetmişle SEO/AEO/GEO optimizasyonu ve yüzde altmış beşle prompt mühendisliği izlemektedir.
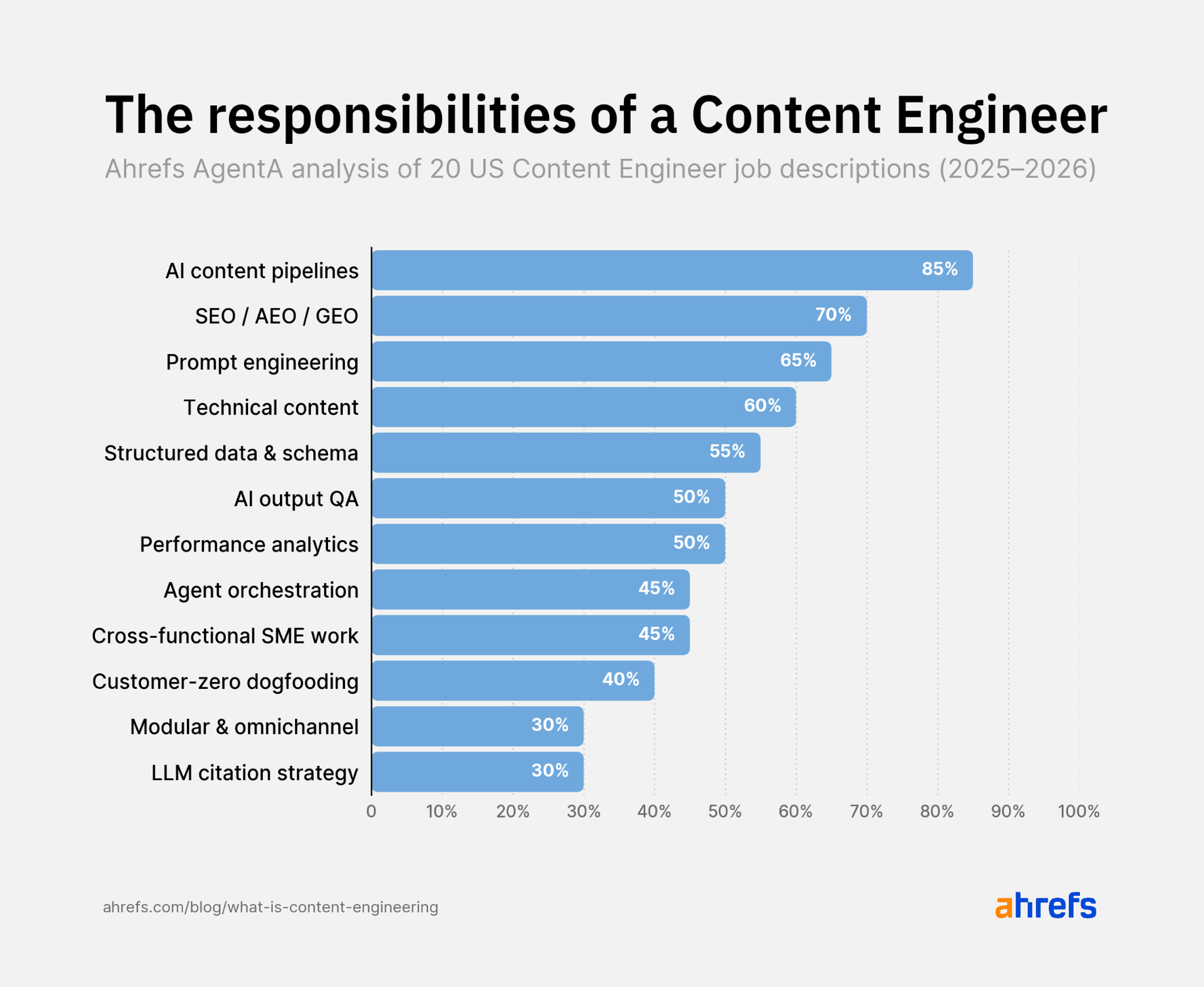
Başka bir deyişle içerik mühendisi, yazmayı da bilen bir sistem kurucusudur; yapay zekayı kullanmayı öğrenen bir yazar değil. Bu ayrım önemlidir çünkü rolün başarısı bireysel içerik parçalarıyla değil, ekibin toplamda ne kadar verimli ve kaliteli çalıştığıyla ölçülür.

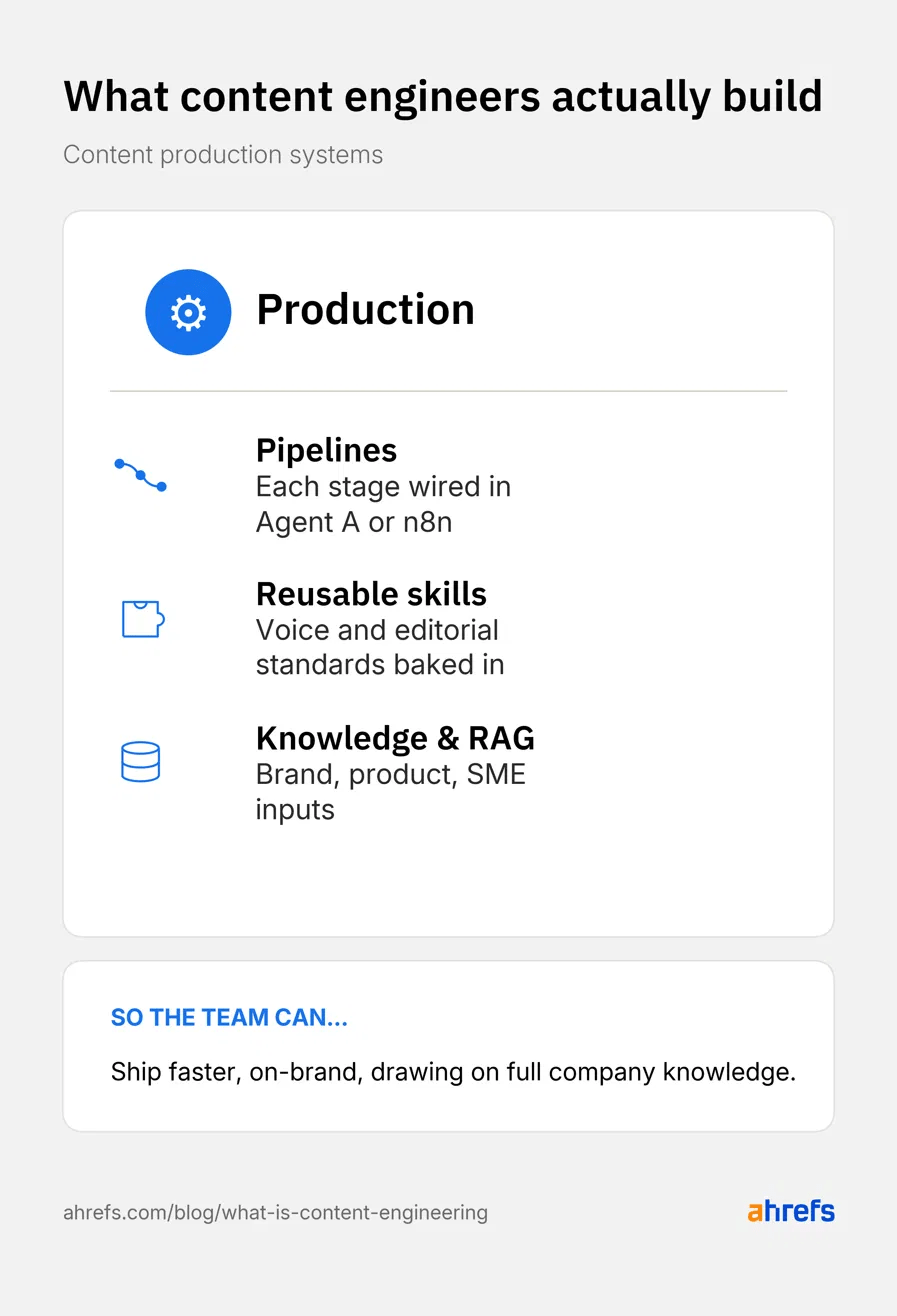
İçerik üretimi
Çoğu içerik ekibi, manuel olarak üretebilecekleri içerik miktarı konusunda bir tavana ulaşır. İçerik üretim mühendisliği bu tavanı yukarı kaldırır. Üretim mühendisleri, araştırmadan ölçüme kadar her aşamayı haritalayan ve bunları birbirine bağlayan pipeline'lar kurar; bu sayede kimse içeriğe sıfırdan başlamak zorunda kalmaz.
Tekrar kullanılabilir beceriler, prompt'lar ve özel talimatlar, ekibin kolektif bilgi birikimini kodlar. Ses tonu, yapı ve editoryal standartlar artık tek bir kişinin kafasında değil, sistemin içinde yaşar. Tüm ekip aynı kalite çıtasına ulaşabilir. Bunun ötesinde, iç bilgi tabanları, gerçek kaynak sistemleri ve RAG yapıları; marka yönergeleri, ürün dokümanları, ideal müşteri profilleri, konumlandırma çerçeveleri, tescilli araştırmalar ve konu uzmanı röportajlarıyla doldurulur. Pipeline, eğitim verilerinden gelen jenerik dil yerine şirketin tam bilgi birikimini kullanır.
İçerik bakımı
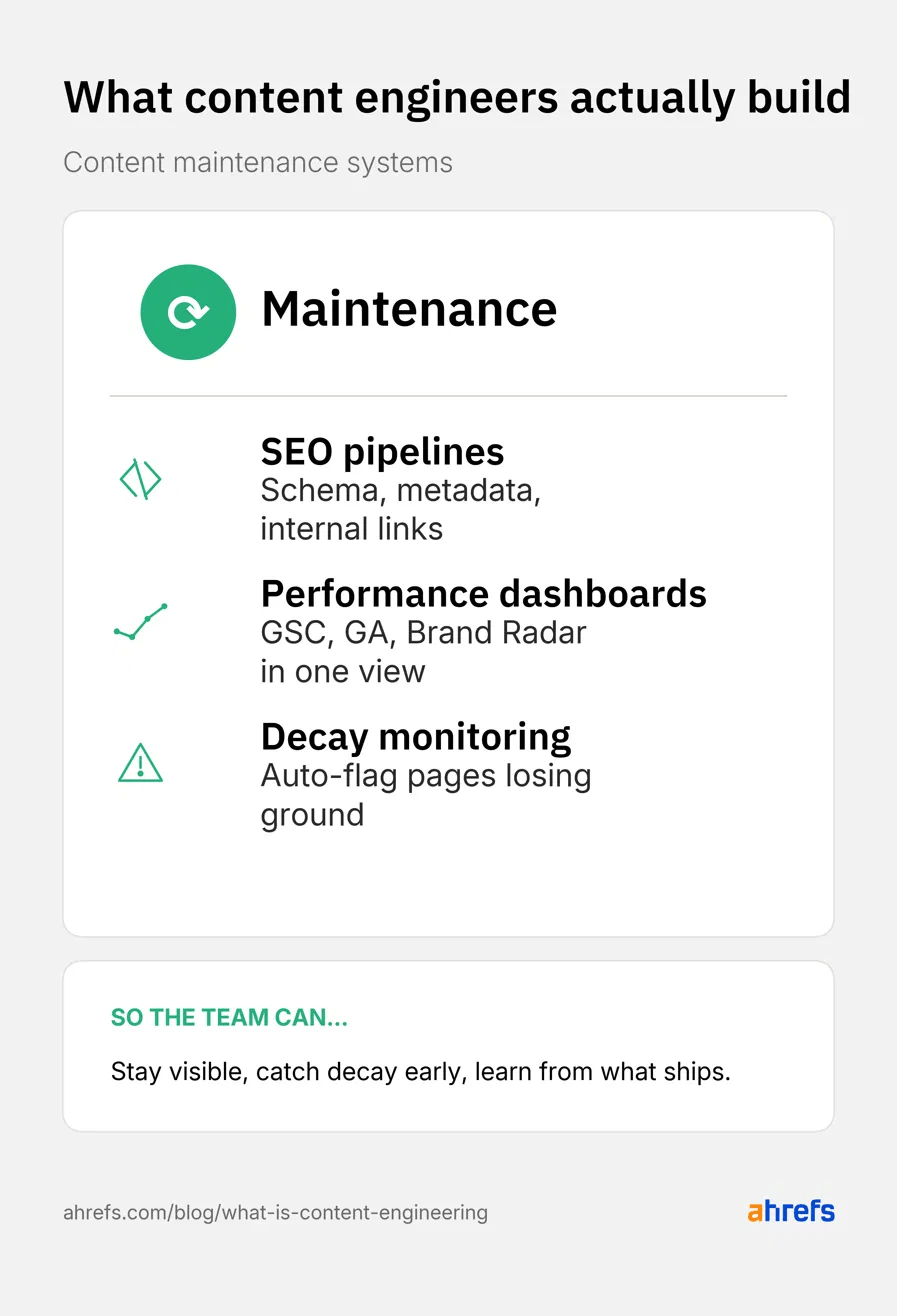
İçerik mühendisliği yalnızca yeni içerik üretmekle sınırlı değildir; yayınlanmış içeriğin zaman içinde performans göstermeye devam etmesini sağlamak da bu rolün temel bir parçasıdır. Yapı, şema, meta veri ve dahili bağlantı kurallarını sayfa sayfa değil şablon düzeyinde belirleyen otomatik SEO pipeline'ları, içeriğin hem arama hem de yapay zeka yüzeylerinde görünür kalmasını sağlar.
Trafik ve yapay zeka görünürlük verilerini tek bir haftalık görünüme toplayan performans panoları ve geri besleme döngüleri, bir sonraki kararı verilere dayandırmanın temelini oluşturur. Hangi içeriğin emekli edileceğini, hangisinin yenileneceğini ve hangisinin genişletileceğini veri destekli bir şekilde belirlemek, içerik takvimine stratejik bir disiplin kazandırır.
Sıralama, trafik veya yapay zeka alıntı kaybeden sayfaları önceden fark eden ve bunları güncelleme kuyruğuna ekleyen içerik çürüme izleme ve yenileme tetikleyicileri, reaktif çalışmayı proaktif bir sisteme dönüştürür. Taze istatistikler eklemek, yeni örnekler dahil etmek veya ek dahili bağlantılar kurmak gibi küçük müdahaleler bile sıralamanın korunması açısından kritik fark yaratabilir.
İçerik dağıtımı
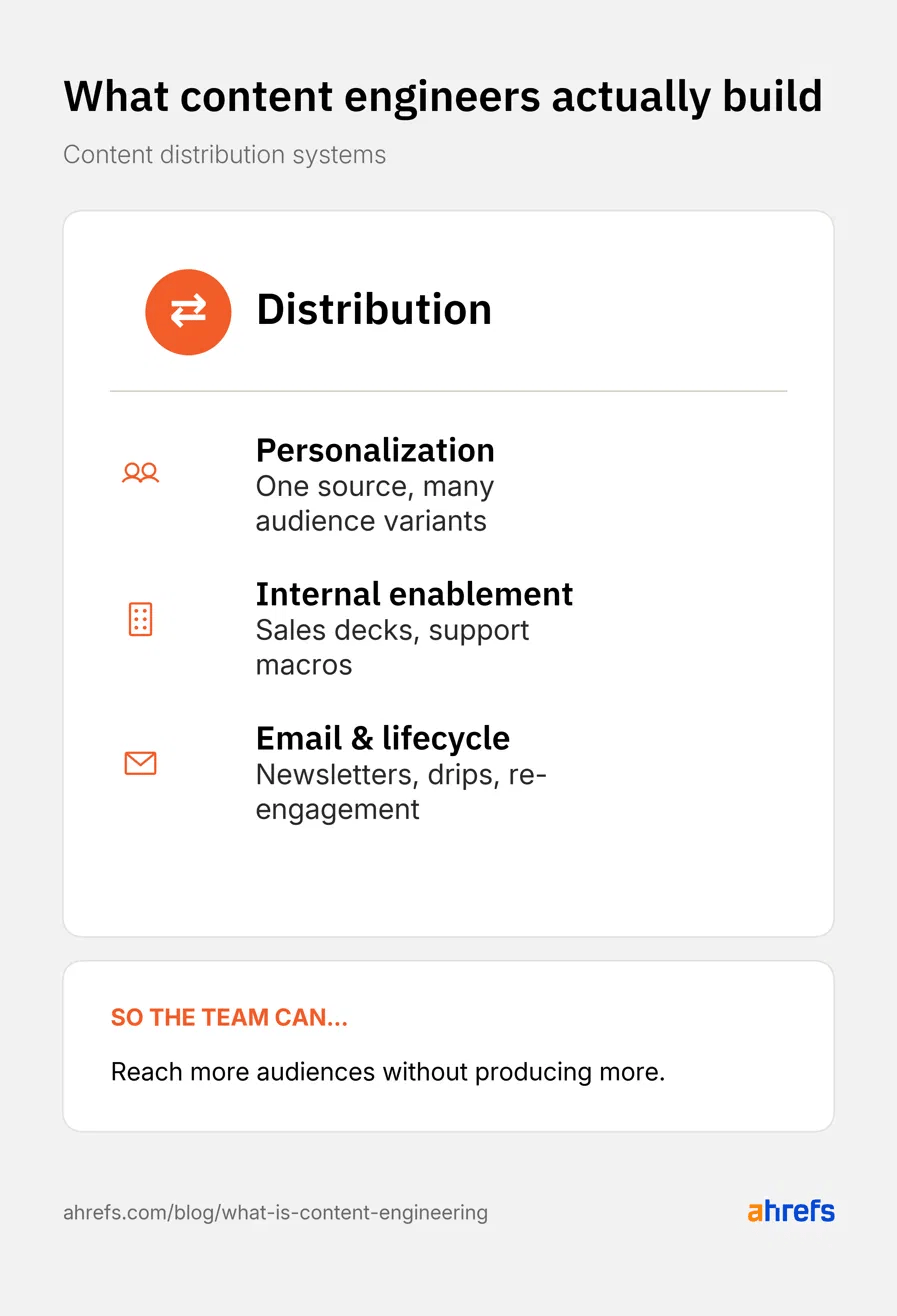
Çoğu içerik yayınlanır, indekslenir, sonra unutulur. İçerik dağıtım mühendisliği, aynı kaynak materyalin düzinelerce temas noktasını beslemesini mümkün kılar. Tek bir kaynak parçayı farklı sektörlere, rollere veya yaşam döngüsü aşamalarına hitap eden versiyonlara dönüştüren kişiselleştirme ve segmentasyon iş akışları bunun somut örneğidir; yerel örnekler ve özelleştirilmiş eylem çağrıları otomatik olarak değiştirilir.
Yayınlanan içeriği diğer ekiplerin kullandığı sistemlere yönlendiren dahili etkinleştirme pipeline'ları, içeriğin yalnızca pazarlama kanalında değil satış sunumlarında, rekabet kartlarında, işe alım e-postalarında ve destek makrolarında da hayat bulmasını sağlar. İçerik yayın noktasında ölmek yerine organizasyonun tamamında değer üretmeye devam eder.
E-posta ve yaşam döngüsü orkestrasyon iş akışları ise yayınlananları ve her alıcının daha önce okuduklarını temel alarak ilgili içeriği bültenlere, damla kampanyalarına ve yeniden etkileşim dizilerine otomatik olarak ekler. Bu otomasyon, içerik ekibinin dağıtım operasyonundan soyutlanarak yeni içerik stratejisine odaklanmasına zemin hazırlar.
İçeriği altı adımda nasıl mühendis edersiniz?
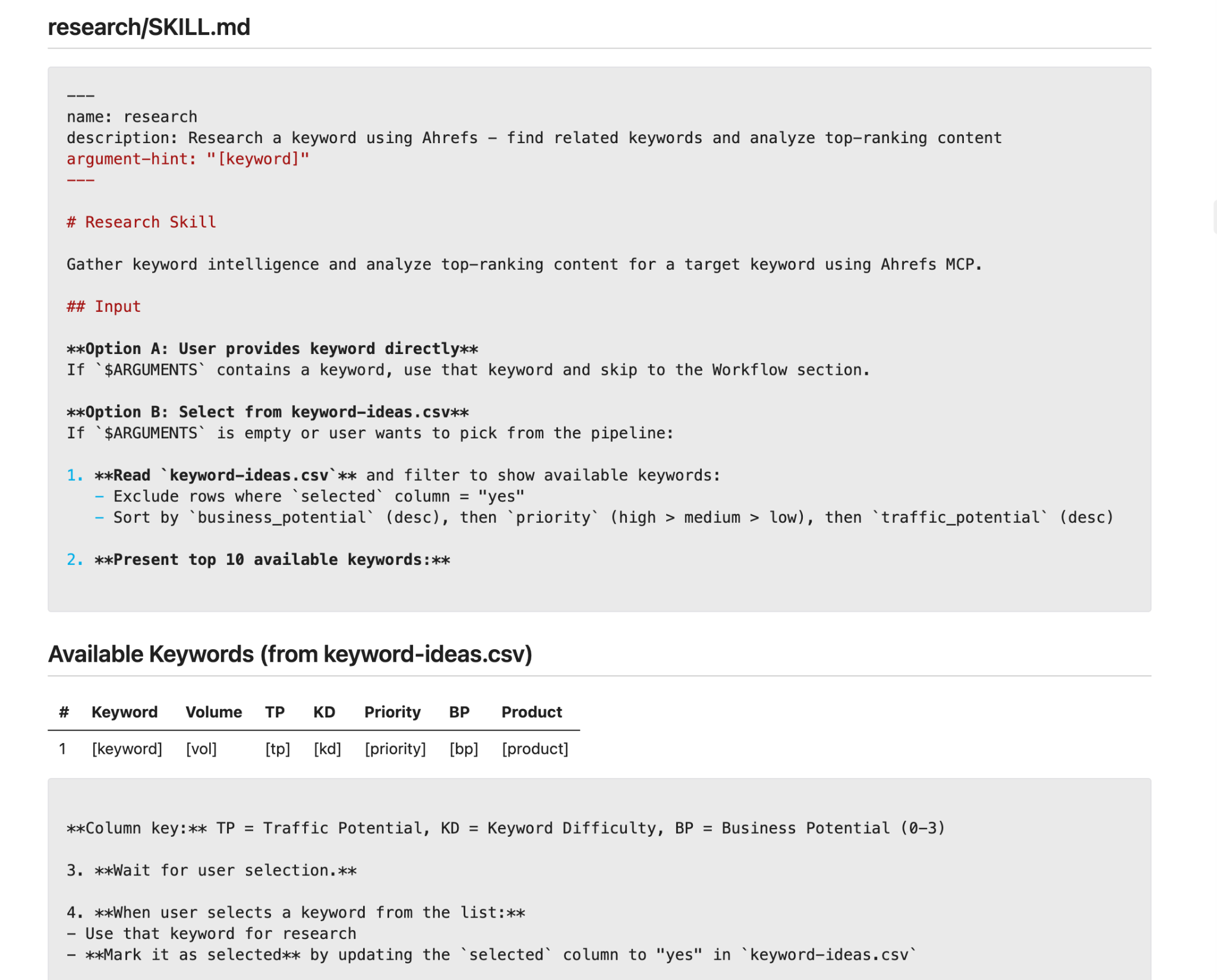
Her pipeline'ın temeli aynı iskelet üzerine kuruludur: altı beceri, bir ana beceri. Kurulum bir öğleden sonraya sığar ve bir kez oturduğunda üzerine sonsuz beceri eklenebilir. Başlamadan önce bir yapay zeka kodlama ortamı kurulur, SEO MCP bağlantısı yapılandırılır ve content-pipeline adlı bir klasör oluşturulur. Bu klasörün içinde .claude/skills/ alt dizini ve 1-research/'ten 6-performance/'a kadar numaralandırılmış altı alt klasör yer alır. Her beceri bir önceki klasörden okur ve bir sonrakine yazar.
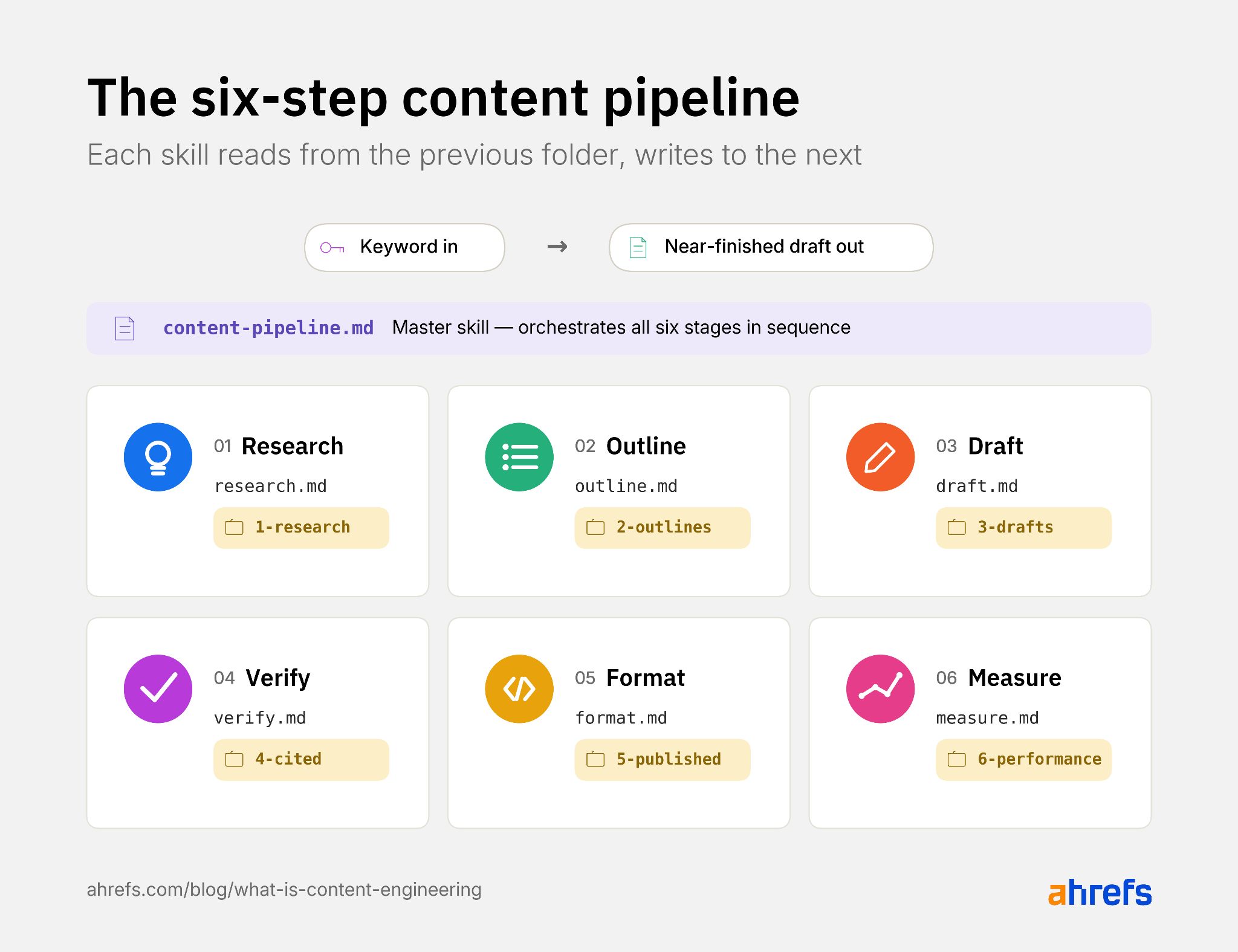
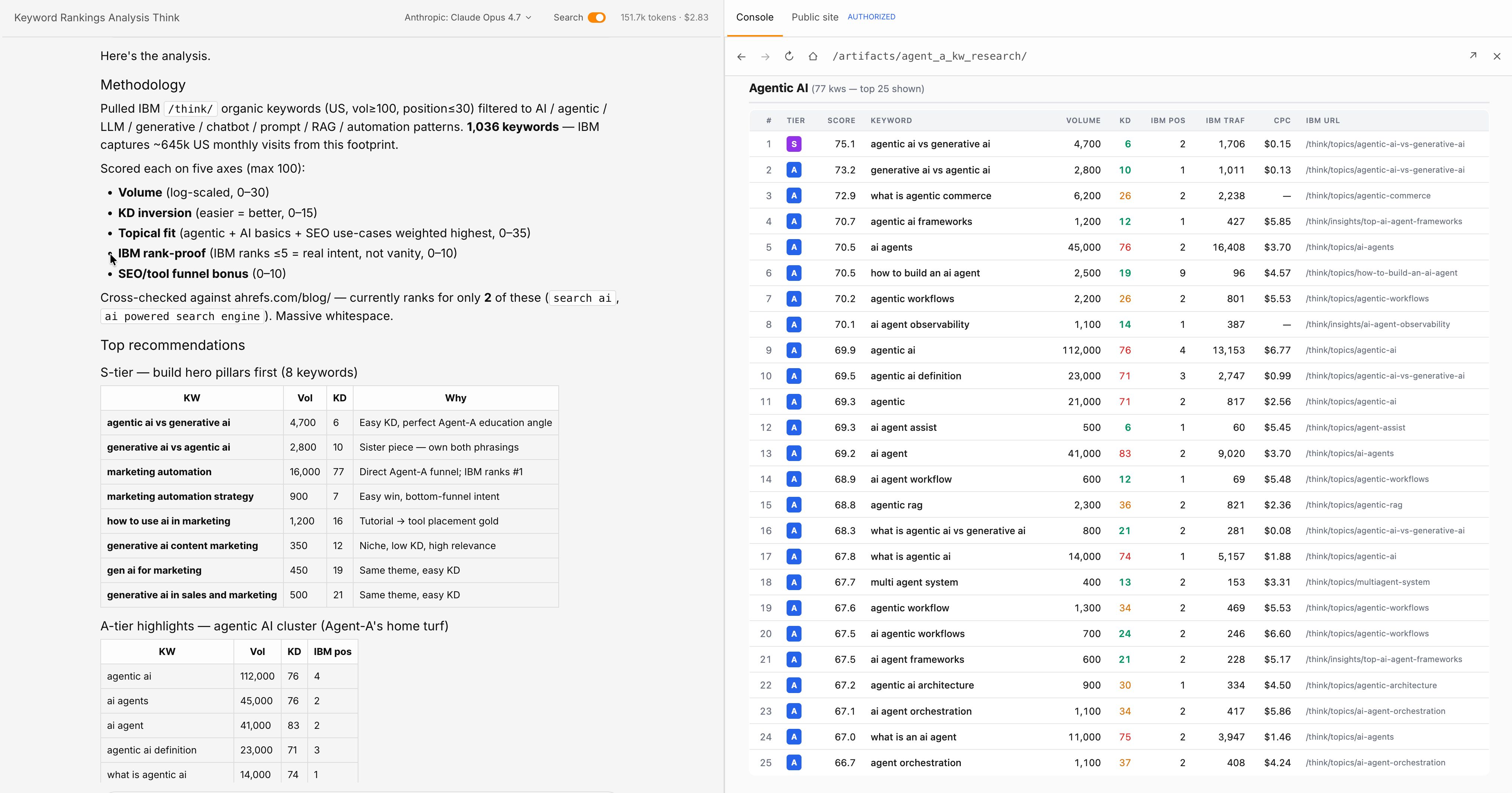
Aşama 1 — Araştırma: Bu beceri bir anahtar kelime alır ve anahtar kelime hacmi, zorluk skoru, üst konu, ilk 10 SERP sonucu ve sık sorulan sorular raporundan oluşan bir Markdown dosyası üretir; tüm veriler bir SEO MCP aracılığıyla canlı olarak çekilir. Becerinin kendisi yalnızca düz Markdown formatında doğal dil talimatlarından ibarettir.
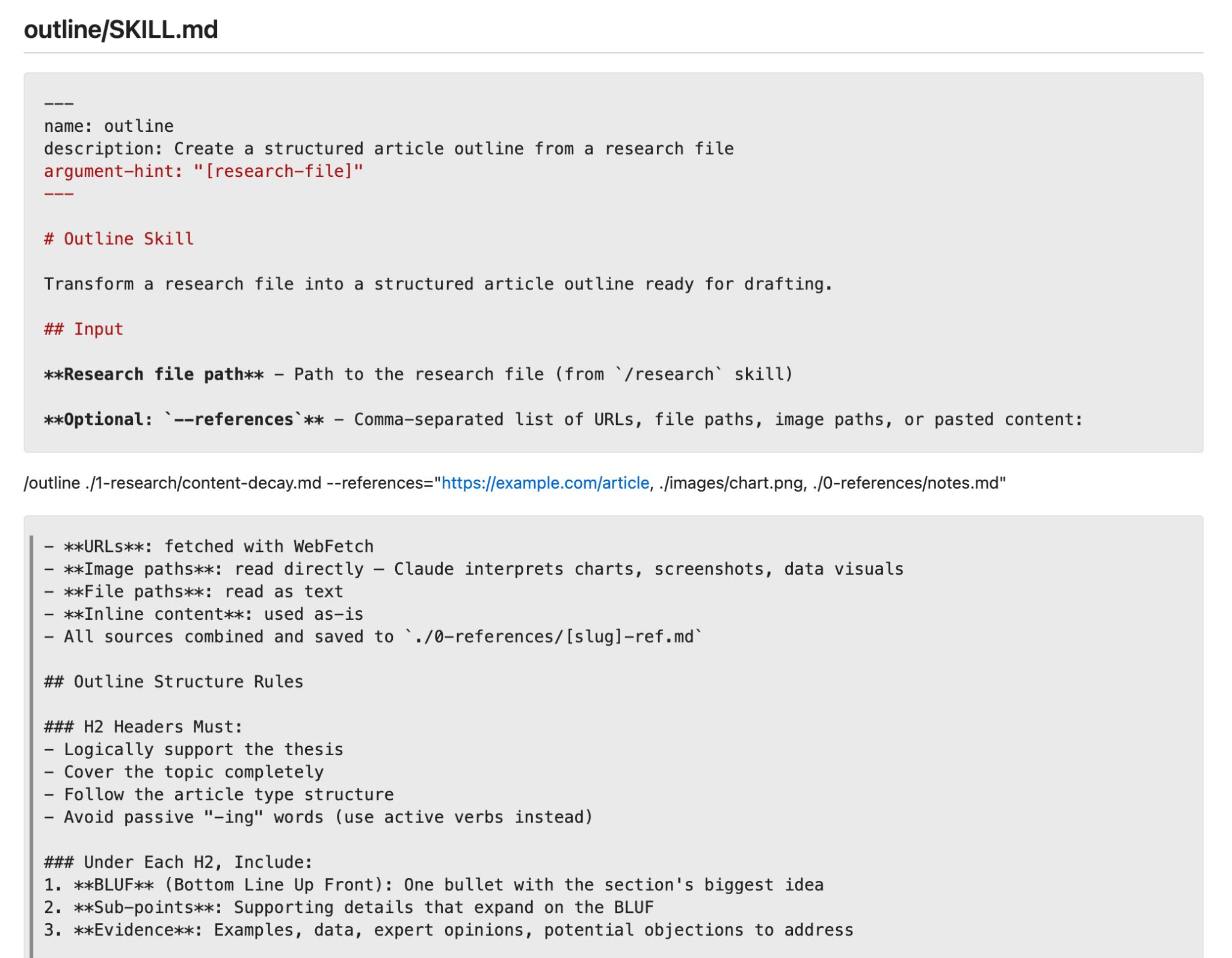
Aşama 2 — Ana Hat Oluşturma: Bu beceri araştırma dosyasını okur ve her bölüm için hedef kelime sayıları ve tek satırlık notlarla birlikte H2/H3 ana hatlarını üretir. Ev tarzı kılavuzu burada kodlanır: başlık kalıpları, bölüm uzunlukları, cevabın en başta mı verildiği yoksa sonuca mı götürüldüğü. Kıdemli bir yazarın normalde her parça için vereceği editoryal kararlar burada bir kez verilir ve her seferinde otomatik olarak uygulanır.

Aşama 3 — Taslak Oluşturma: Bu beceri ana hattı okur ve tam bir ilk taslak üretir. Taslak becerisi, yayınlanmış en iyi iki veya üç makaleyi içeren bir /examples/ klasörüne başvurmalıdır. Bu olmadan çıktı varsayılan yapay zeka diline kayar. Örneklerle birlikte sistem cümle ritminizi, paragraf uzunluğunuzu ve yazıyı size ait hissettiren küçük üslup tercihlerinizi özümser.
Aşama 4 — Doğrulama: Bu beceri taslağı kaynak gösterilmemiş iddialar için tarar ve bunları alıntılar ya da işaretler. İstatistikler, tarihler, adlandırılmış çalışmalar ve alıntılanan rakamları arar, ardından her biri için birincil kaynaklar bulur. Kaynak bulunursa satır içi bağlantı eklenir; kaynak bulunamazsa iddia [UNVERIFIED] etiketiyle işaretlenerek bir insan kararı için bırakılır. Bu aşama, hataların yayına ulaşmasını önleyen güvenlik ağıdır.
Aşama 5 — Biçimlendirme: Bu beceri doğrulanmış taslağa CMS'in yapısal gereksinimlerini uygular ve kısa kodlar, şema ve dahili bağlantılar uygulanmış CMS'e hazır bir sürüm çıktısı verir. Bu aşama ne kadar ileri götürülürse yayından sonra o kadar az manuel temizlik gerekir. WordPress bağlayıcısı, biçimlendirilmiş çıktıyı doğrudan taslak gönderiye itebilir.
Aşama 6 — Ölçüm: Bu beceri her yayınlanan parça üzerinde aylık olarak çalışır. Arama Konsolu, GA ve yapay zeka arama görünürlük araçlarından trafik, sıralama ve yapay zeka alıntı verilerini çekecek ve bozunan parçaları yenileme için işaretleyecek şekilde kurulabilir. Bu aşama sistemi öğrenen bir yapıya kavuşturur: birinci döngüde işe yarayan ikinci döngüyü bilgilendirir; ikinci döngü üçüncüyü şekillendirir. Birkaç iterasyonun ardından gerçekten yayınlamak isteyeceğiniz taslaklar üreten bir pipeline elde edersiniz.
Hangi içerik mühendisliğe uygun? Yapay zeka pipeline'ları özellikle tekrar eden, yeniden amaçlanan veya şablonlu içeriklerde; yapısı öngörülebilir bilgilendirici içeriklerde; tescilli veriye dayanan içeriklerde; uzun ömürlü evergreen konularda ve şablondan üretilen programatik içeriklerde en iyi sonucu verir. Öte yandan yapay zekanın haklı olup olmadığını doğrulayamayacağınız, derin uzmanlık gerektiren konularda veya orijinal bakış açısının tüm değeri oluşturduğu içeriklerde ham pipeline çıktısına güvenmek riskli olabilir.
| Pipeline Aşaması | Giriş | Çıkış | Temel Beceri |
|---|---|---|---|
| 1 – Araştırma | Anahtar kelime | Markdown veri dosyası | SEO MCP sorgusu |
| 2 – Ana Hat | Araştırma dosyası | H2/H3 ana hat + kelime hedefleri | Editoryal stil kuralları |
| 3 – Taslak | Ana hat + örnek makaleler | İlk taslak | Ses tonu örnekleri |
| 4 – Doğrulama | Ham taslak | Kaynaklanmış veya işaretlenmiş taslak | Birincil kaynak araması |
| 5 – Biçimlendirme | Doğrulanmış taslak | CMS'e hazır dosya | Şema + dahili bağlantı kuralları |
| 6 – Ölçüm | Yayınlanan URL | Performans raporu + yenileme listesi | GSC + GA + görünürlük verisi |
Bu tablo, temel altı aşamalı içerik pipeline'ının her adımda neleri dönüştürdüğünü özetlemektedir.

Oktay Çomak
Kurucu & SEO Stratejisti, SEOART
Kurumsal SEO'da veri disiplini ve ölçülebilir iş etkisine odaklanıyoruz; yol haritanızı birlikte netleştirelim.
LinkedInSEO yol haritanızı birlikte çizelim
Teknik sağlık, içerik uyumu ve görünürlük için ücretsiz ön analiz talep edin; öncelikli bulgularla sonraki adımları konuşalım.